必要的配置
本页面由 PageTurner AI 翻译(测试版)。未经项目官方认可。 发现错误? 报告问题 →
This section gives you the best practices to optimize our crawl. Adopting the following specification is required to let our crawler build the best experience from your website. You will need to update your website and follow these rules.
如果您的网站由我�们支持的工具生成,则无需修改网站,因为它已符合我们的要求。
通用配置示例
您可以在下方找到默认的 DocSearch 配置模板,并参考complex extractors章节中的示例进行调整。
docsearch-default.js
new Crawler({
appId: 'YOUR_APP_ID',
apiKey: 'YOUR_API_KEY',
startUrls: ['https://YOUR_START_URL.io/'],
sitemaps: ['https://YOUR_START_URL.io/sitemap.xml'],
actions: [
{
indexName: 'YOUR_INDEX_NAME',
pathsToMatch: ['https://YOUR_START_URL.io/**'],
recordExtractor: ({ helpers }) => {
return helpers.docsearch({
recordProps: {
lvl0: {
selectors: '',
defaultValue: 'Documentation',
},
lvl1: ['header h1', 'article h1', 'main h1', 'h1', 'head > title'],
lvl2: ['article h2', 'main h2', 'h2'],
lvl3: ['article h3', 'main h3', 'h3'],
lvl4: ['article h4', 'main h4', 'h4'],
lvl5: ['article h5', 'main h5', 'h5'],
lvl6: ['article h6', 'main h6', 'h6'],
content: ['article p, article li', 'main p, main li', 'p, li'],
},
aggregateContent: true,
recordVersion: 'v3',
});
},
},
],
initialIndexSettings: {
YOUR_INDEX_NAME: {
attributesForFaceting: ['type', 'lang'],
attributesToRetrieve: [
'hierarchy',
'content',
'anchor',
'url',
'url_without_anchor',
'type',
],
attributesToHighlight: ['hierarchy', 'content'],
attributesToSnippet: ['content:10'],
camelCaseAttributes: ['hierarchy', 'content'],
searchableAttributes: [
'unordered(hierarchy.lvl0)',
'unordered(hierarchy.lvl1)',
'unordered(hierarchy.lvl2)',
'unordered(hierarchy.lvl3)',
'unordered(hierarchy.lvl4)',
'unordered(hierarchy.lvl5)',
'unordered(hierarchy.lvl6)',
'content',
],
distinct: true,
attributeForDistinct: 'url',
customRanking: [
'desc(weight.pageRank)',
'desc(weight.level)',
'asc(weight.position)',
],
ranking: [
'words',
'filters',
'typo',
'attribute',
'proximity',
'exact',
'custom',
],
highlightPreTag: '<span class="algolia-docsearch-suggestion--highlight">',
highlightPostTag: '</span>',
minWordSizefor1Typo: 3,
minWordSizefor2Typos: 7,
allowTyposOnNumericTokens: false,
minProximity: 1,
ignorePlurals: true,
advancedSyntax: true,
attributeCriteriaComputedByMinProximity: true,
removeWordsIfNoResults: 'allOptional',
separatorsToIndex: '_',
},
},
});
清晰布局概览
A website implementing these best practices will look simple and clear, as shown below:
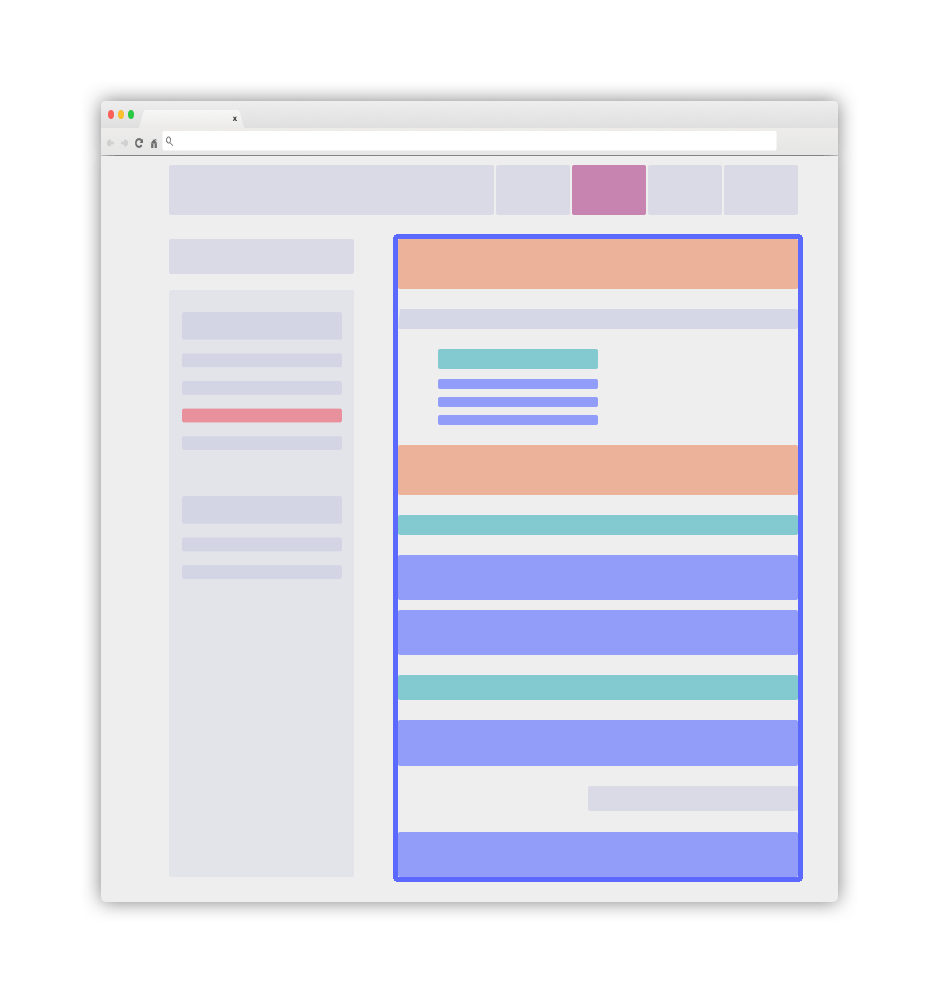
主要的蓝色元素将是您的 .DocSearch-content 容器。更多细节请参考后续指南。
使用正确的类作为 recordProps
您可以添加特定的静态 CSS 类来帮助我们识别内容角色。这些类不应引起样式变化,而是专门用于在文档中实现即输即学的优质体验。
-
在文本内容的主容器添加静态类
DocSearch-content。该容器通常是<main>或<article>HTML 元素。 -
主文档容器外部的所有可搜索
lvl元素(例如侧边栏中)必须使用global选择器。它们将被全局采集并注入到页面生成的所有记录中。注意:层级值至关重要,所有匹配元素必须沿 HTML 流递增。层级X(对应lvlX)应出现在层级Y之后,且满足X > Y。 -
lvlX选择器应使用标准标题标签如h1,h2,h3等,也可使用静态类。请按以下要求为这些元素设置唯一的id或name属性。 -
所有匹配
lvlX选择器的 DOM 元素必须具备唯一的id或name属性。这能确保重定向时精确滚动到目标位置,这些属性定义了正确的锚点。 -
所有文本元素(recordProps 的
content)必须包裹在<p>或<li>标签中。内容应保持原子化并拆分为小单元。注意避免嵌套匹配元素,否则会产生重复记录。 -
保持一致性,确保整个 HTML 流中遵循统一规范。
通过 meta 标签添加全局信息
我们的爬虫会自动提取 DocSearch 专属 meta 标签中的信息:
<meta name="docsearch:language" content="en" />
<meta name="docsearch:version" content="1.0.0" />
爬虫会将这些 meta 标签的 content 值添加到页面提取的所有记录中。meta 标签的 name 必须遵循 docsearch:$NAME 模式,其中 $NAME 是设置到所有记录的属性名。
docsearch:version meta 标签可以是逗号分隔的标记集合,每个标记代表页面相关的版本。这些标记必须符合SemVer 规范或仅包含字母数字字符(如 latest, next 等)。作为分面过滤器,这些版本标记不区分大小写。
例如,包含以下 meta 标签的页面所提取的所有记录:
<meta name="docsearch:version" content="2.0.0-alpha.62,latest" />
这些记录的 version 属性将为:
version:["2.0.0-alpha.62", "latest"]
您可将这些属性转换为 facetFilters,从而在 UI 界面上进行筛选。
推荐优化项
-
您的网站应提供更新的站点地图。�这是让爬虫识别更新内容的关键。无需担心,我们仍会通过爬取网站并发现内嵌超链接来获取精彩内容。
-
每个页面都需要提供完整的上下文信息。使用全局元素会很有帮助(参见上文说明)。
-
确保文档内容在客户端无需JavaScript渲染即可访问。若必须启用JavaScript,则需在配置中设置
renderJavaScript: true。