必要的配置
本页面由 PageTurner AI 翻译(测试版)。未经项目官方认可。 发现错误? 报告问题 →
本节内容基于我们构建 DocSearch 索引的详细原理,为您提供优化爬取效果的最佳实践。遵循以下规范是确保爬虫从您网站构建最佳搜索体验的必要条件,您需要按照这些规则调整网站结构。
注意:若您的网站使用我们支持的生成工具构建,则无需调整,因其已满足我们的要求。
通用配置示例
{
"index_name": "example",
"start_urls": ["https://www.example.com/doc/"],
"sitemap_urls": ["https://www.example.com/sitemap.xml"],
"stop_urls": [],
"selectors": {
"lvl0": {
"selector": ".DocSearch-lvl0",
"global": true,
"default_value": "Documentation"
},
"lvl1": {
"selector": ".DocSearch-lvl1",
"global": true,
"default_value": "Chapter"
},
"lvl2": ".DocSearch-content .DocSearch-lvl2",
"lvl3": ".DocSearch-content .DocSearch-lvl3",
"lvl4": ".DocSearch-content .DocSearch-lvl4",
"lvl5": ".DocSearch-content .DocSearch-lvl5",
"lvl6": ".DocSearch-content .DocSearch-lvl6",
"text": ".DocSearch-content p, .DocSearch-content li"
},
"custom_settings": {
"attributesForFaceting": ["language", "version"]
},
"nb_hits": "OUTPUT OF THE CRAWL"
}
清晰布局概览
采用这些最佳实践的网站将呈现简洁清晰的结构,可参考如下示例:
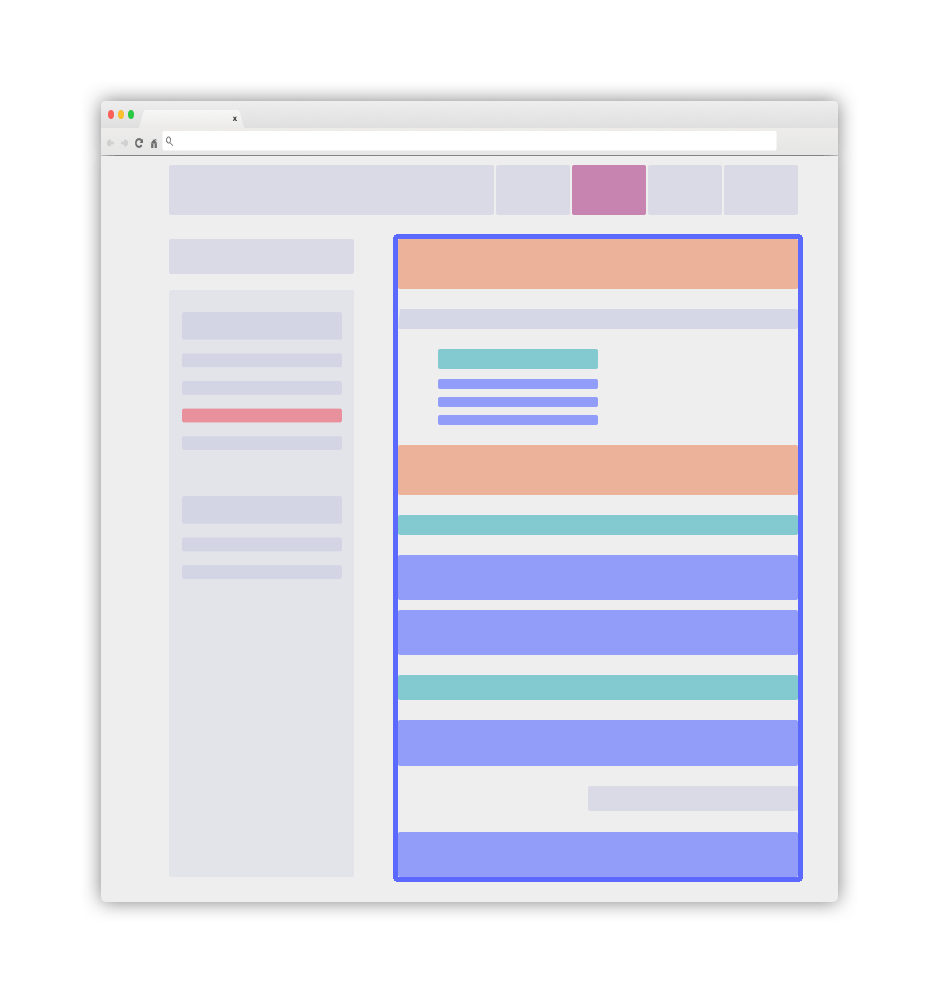
主要的蓝色元素将是您的 .DocSearch-content 容器。更多细节请参考后续指南。
正确使用选择器作为标记
您可以添加特定的静态 CSS 类来帮助我们识别内容角色。这些类不应引起样式变化,而是专门用于在文档中实现即输即学的优质体验。
-
在文本内容的主容器添加静态类
DocSearch-content。该容器通常是<main>或<article>HTML 元素。 -
主文档容器外部的所有可搜索
lvl元素(例如侧边栏中)必须使用global选择器。它们将被全局采集并注入到页面生成的所有记录中。注意:层级值至关重要,所有匹配元素必须沿 HTML 流递增。层级X(对应lvlX)应出现在层级Y之后,且满足X > Y。 -
lvlX选择器应使用标准标题标签如h1,h2,h3等,也可使用静态类。请按以下要求为这些元素设置唯一的id或name属性。 -
所有匹配
lvlX选择器的 DOM 元素必须具有唯一的id或name属性,确保跳转时能精准定位到对应元素位置,这些属性定义了正确的锚点。 -
所有文本元素(选择器
text)必须包裹在<p>或<li>标签内。内容应原子化拆分,避免嵌套匹配元素导致重复记录。 -
保持一致性,确保 HTML 流中元素层级关系符合此文档所述规范。
通过 meta 标签添加全局信息
我们的爬虫会自动提取 DocSearch 专属 meta 标签中的信息:
<meta name="docsearch:language" content="en" />
<meta name="docsearch:version" content="1.0.0" />
爬虫会将这些 meta 标签的 content 值添加到页面提取的所有记录中。meta 标签的 name 必须遵循 docsearch:$NAME 模式,其中 $NAME 是设置到所有记录的属性名。
您可将这些属性转化为 facetFilters,在 UI 层进行过滤筛选。需在 Algolia 索引中设置 attributesForFaceting 参数,并通过DocSearch 的 custom_settings 配置提交 PR。
"custom_settings": {
"attributesForFaceting": ["language", "version"]
}
此机制支持按 meta 标签值过滤记录,以下示例演示如何更新 JavaScript 片段以获取这些页面的记录。
docsearch({
[…],
algoliaOptions: {
'facetFilters': ["language:en", "version:1.0.0"]
},
[…],
});
docsearch:version meta 标签可以是逗号分隔的标记集合,每个标记代表页面相关的版本。这些标记必须符合SemVer 规范或仅包含字母数字字符(如 latest, next 等)。作为分面过滤器,这些版本标记不区分大小写。
例如,包含以下 meta 标签的页面所提取的所有记录:
<meta name="docsearch:version" content="2.0.0-alpha.62,latest" />
这些记录的 version 属性将为:
version:["2.0.0-alpha.62" , "latest"]
推荐优化项
-
您的网站应提供更新的站点地图。这是让爬虫识别更新内容的关键。无需担心,我们仍会通过爬取网站并发现内嵌超链接来获取精彩内容。
-
每个页面都需要提供完整的上下文信息。使用全局元素会很有帮助(参见上文说明)。
-
确保文档内容在不启用客户端 JavaScript 的情况下仍可访问。若必须使用 JavaScript,请在配置中设置
js_render: true。