Améliorer la qualité des réponses avec l'indexation Markdown
Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →
Pour fournir des réponses plus précises et riches en contexte à grande échelle, Ask AI bénéficie d'un contenu proprement structuré. L'une des méthodes les plus efficaces pour y parvenir est d'utiliser un assistant d'indexation basé sur Markdown dans votre configuration du Crawler Algolia. Cette configuration garantit qu'Ask AI peut accéder à des enregistrements bien formés et centrés sur le contenu, ce qui est particulièrement important pour les sites de documentation volumineux où les métadonnées, les éléments de navigation ou les artefacts de mise en page pourraient autrement diluer la qualité des réponses génératives.
La configuration de l'indexation Markdown peut être automatisée via l'interface du Crawler pour la plupart des cas d'usage. Pour des personnalisations avancées ou pour comprendre la configuration sous-jacente, des options de configuration manuelle sont également disponibles.
Remarque : Pour plus d'exemples d'intégration (Docusaurus, VitePress, Astro/Starlight et configurations génériques), consultez la section en bas de cette page.
Vue d'ensemble
Pour maximiser la qualité des réponses d'Ask AI, configurez votre Crawler pour créer un index dédié au contenu Markdown. Cette approche permet à Ask AI de travailler avec des enregistrements structurés et découpés provenant de votre documentation, de contenu d'assistance ou de tout matériel basé sur Markdown, ce qui aboutit à des réponses nettement plus pertinentes et précises.
Vous pouvez configurer l'indexation Markdown de deux manières :
-
Configuration automatisée (recommandée) : Utilisez l'interface du Crawler pour créer et configurer automatiquement votre index Markdown
-
Configuration manuelle : Configurez manuellement votre Crawler pour des besoins de personnalisation avancée
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
Configuration automatisée de l'indexation Markdown (recommandée)
La manière la plus simple de configurer l'indexation Markdown est via l'interface du Crawler, qui crée et configure automatiquement un index Markdown optimisé pour Ask AI.
Étape 1 : Accéder à l'indexation Markdown dans la configuration du Crawler
-
Accédez à votre tableau de bord du Crawler
-
Rendez-vous dans l'onglet Configuration → Markdown pour LLMs
-
Vous verrez la section d'indexation Markdown où vous pouvez créer un index dédié
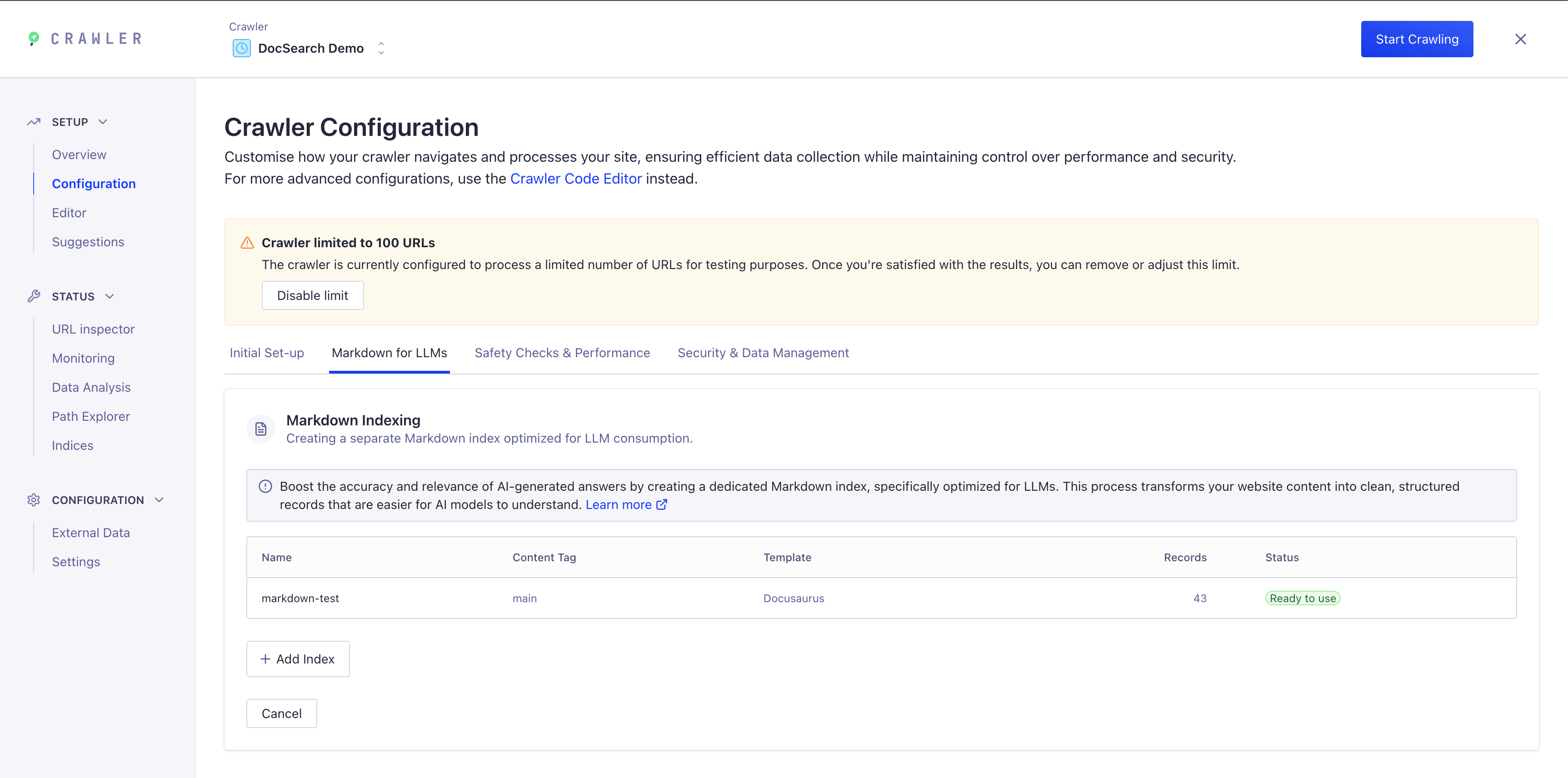
Étape 2 : Ajouter un nouvel index Markdown
-
Cliquez sur "+ Ajouter un index" pour créer un nouvel index Markdown
-
Fill in the required fields:
- Index Name: Enter a descriptive name (e.g.,
my-docs-markdown) - Content Tag: Specify the HTML content selector (typically
main) - Template: Choose the template that matches your documentation framework:
- Docusaurus - For Docusaurus sites
- VitePress - For VitePress sites
- Astro/Starlight - For Astro/Starlight sites
- Non-DocSearch (Generic) - For custom sites or other frameworks
- Index Name: Enter a descriptive name (e.g.,
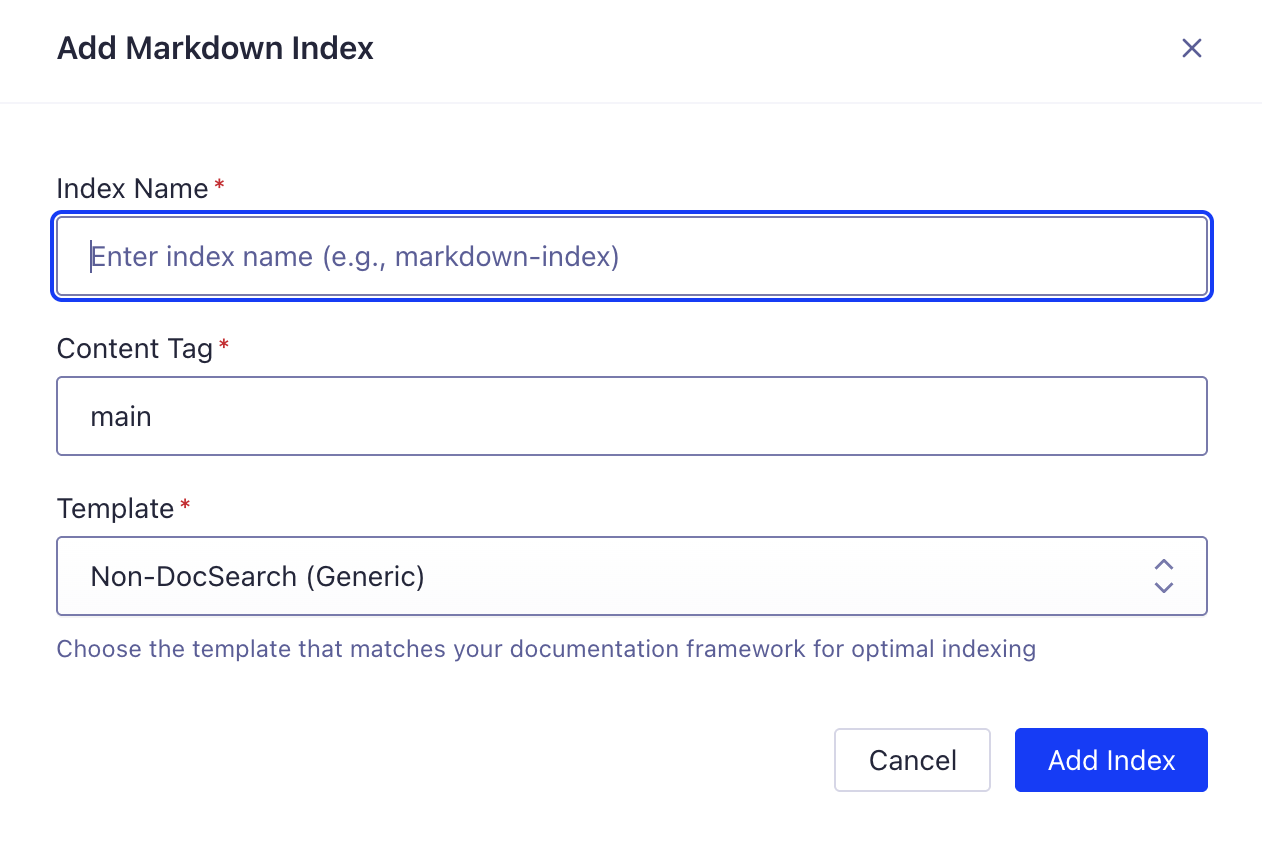
- Cliquez sur "Ajouter l'index" pour le créer
Le Crawler configurera automatiquement les paramètres optimaux pour votre modèle choisi, notamment :
-
L'extraction et le découpage appropriés des enregistrements
-
L'extraction des métadonnées spécifiques au framework (langue, version, tags)
-
Paramètres d'index optimisés pour Ask AI
Étape 3 : Exécuter le Crawler
Une fois votre index Markdown configuré :
-
Cliquez sur "Démarrer l'exploration" pour commencer l'indexation de votre contenu
-
Surveillez la progression dans le tableau de bord
-
Votre nouvel index Markdown sera rempli d'enregistrements propres et structurés optimisés pour Ask AI
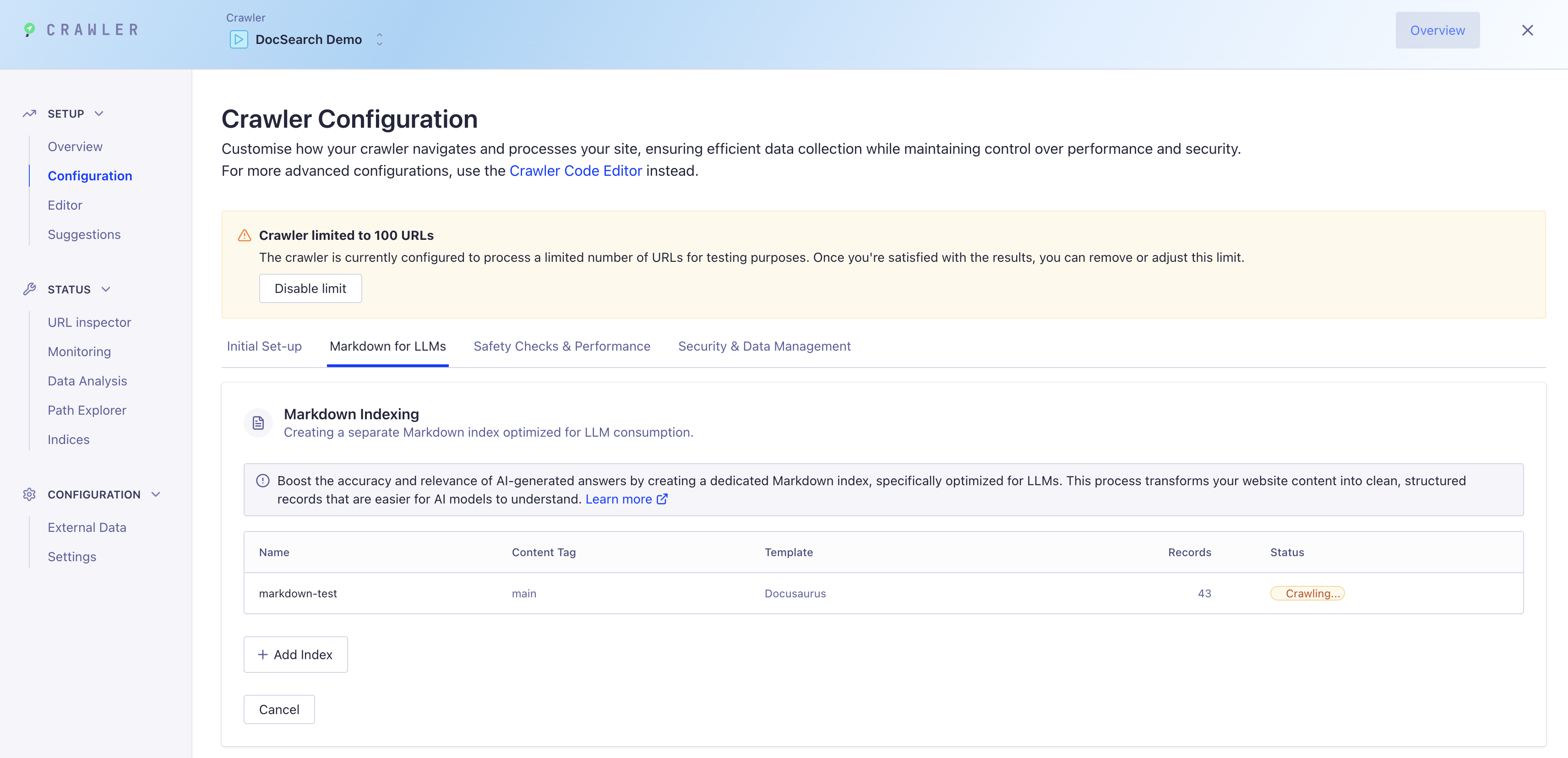
Étape 4 : Intégrer avec Ask AI
Une fois l'exploration terminée, configurez DocSearch pour utiliser votre nouvel index Markdown pour les réponses d'Ask AI. Consultez la section d'intégration ci-dessous pour des instructions détaillées de configuration.
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
Configuration manuelle (avancée)
Pour les utilisateurs nécessitant une personnalisation avancée ou souhaitant comprendre la configuration sous-jacente, vous pouvez configurer manuellement l'indexation Markdown en modifiant directement votre configuration de Crawler.
Étape 1 : Mettre à jour votre configuration existante du Crawler DocSearch
- Dans votre configuration de Crawler, ajoutez les éléments suivants à votre tableau
actions: [ ... ]:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language,
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
- Puis ajoutez les éléments suivants à votre objet
initialIndexSettings: { ... }:
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"],
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
Étape 2 : Exécuter le crawler DocSearch pour créer un nouvel index optimisé pour Ask AI
Après avoir mis à jour votre configuration de Crawler :
-
Publiez votre configuration dans le tableau de bord du Crawler Algolia pour l'enregistrer et l'activer.
-
Exécutez le Crawler pour indexer votre contenu Markdown et créer le nouvel index.
Le Crawler traitera votre contenu à l'aide de l'assistant d'extraction Markdown et peuplera votre nouvel index avec des enregistrements propres et structurés optimisés pour Ask AI.
Conseil : Surveillez la progression du crawl dans votre tableau de bord pour vous assurer que toutes les pages sont traitées correctement. Vous pouvez consulter les enregistrements indexés dans votre index Algolia pour vérifier la structure et le contenu.
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
Intégrer votre nouvel index avec Ask AI
Une fois que votre Crawler a créé votre index optimisé, vous pouvez l'intégrer à Ask AI de deux manières : en utilisant DocSearch (recommandé pour la plupart des utilisateurs) ou en créant une intégration personnalisée à l'aide de l'API Ask AI.
- DocSearch Integration
- Custom API Integration
Using DocSearch
Configure DocSearch to use both your main keyword index and your markdown index for Ask AI:
- JavaScript
- React
docsearch({
indexName: 'YOUR_INDEX_NAME', // Main DocSearch keyword index
apiKey: 'YOUR_SEARCH_API_KEY',
appId: 'YOUR_APP_ID',
askAi: {
indexName: 'YOUR_INDEX_NAME-markdown', // Markdown index for Ask AI
apiKey: 'YOUR_SEARCH_API_KEY', // (or a different key if needed)
appId: 'YOUR_APP_ID',
assistantId: 'YOUR_ALGOLIA_ASSISTANT_ID',
searchParameters: {
facetFilters: ['language:en'], // Optional: filter to specific language/version
},
},
});
<DocSearch
indexName="YOUR_INDEX_NAME" // Main DocSearch keyword index
apiKey="YOUR_SEARCH_API_KEY"
appId="YOUR_APP_ID"
askAi={{
indexName: 'YOUR_INDEX_NAME-markdown', // Markdown index for Ask AI
apiKey: 'YOUR_SEARCH_API_KEY',
appId: 'YOUR_APP_ID',
assistantId: 'YOUR_ALGOLIA_ASSISTANT_ID',
searchParameters: {
facetFilters: ['language:en'], // Optional: filter to specific language/version
},
}}
/>
indexName: Your main DocSearch index for keyword search.askAi.indexName: The markdown index you created for Ask AI context.assistantId: The ID of your configured Ask AI assistant.searchParameters.facetFilters: Optional filters to limit Ask AI context (useful for multi-language sites).
Custom API Integration
We highly recommend using the DocSearch package for most use cases. Custom implementations using the Ask AI API directly are not fully supported to the same extent as the DocSearch package, and may require additional development effort for features like error handling, authentication, and UI components.
Build your own chat interface using the Ask AI API. This gives you full control over the user experience and allows for advanced customizations.
class CustomAskAI {
constructor({ appId, apiKey, indexName, assistantId }) {
this.appId = appId;
this.apiKey = apiKey;
this.indexName = indexName; // Your markdown index
this.assistantId = assistantId;
this.baseUrl = 'https://askai.algolia.com';
}
async getToken() {
const response = await fetch(`${this.baseUrl}/chat/token`, {
method: 'POST',
headers: {
'X-Algolia-Assistant-Id': this.assistantId,
},
});
const data = await response.json();
return data.token;
}
async sendMessage(conversationId, messages, searchParameters = {}) {
const token = await this.getToken();
const response = await fetch(`${this.baseUrl}/chat`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Algolia-Application-Id': this.appId,
'X-Algolia-API-Key': this.apiKey,
'X-Algolia-Index-Name': this.indexName, // Use your markdown index
'X-Algolia-Assistant-Id': this.assistantId,
'Authorization': token,
},
body: JSON.stringify({
id: conversationId,
messages,
...(Object.keys(searchParameters).length > 0 && { searchParameters }),
}),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
// Handle streaming response
const reader = response.body.getReader();
const decoder = new TextDecoder();
return {
async *[Symbol.asyncIterator]() {
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
if (chunk.trim()) {
yield chunk;
}
}
} finally {
reader.releaseLock();
}
}
};
}
}
// Usage
const askAI = new CustomAskAI({
appId: 'YOUR_APP_ID',
apiKey: 'YOUR_API_KEY',
indexName: 'YOUR_INDEX_NAME-markdown', // Your markdown index
assistantId: 'YOUR_ASSISTANT_ID',
});
// Send a message with facet filters for your markdown index
const stream = await askAI.sendMessage('conversation-1', [
{
role: 'user',
content: 'How do I configure my API?',
id: 'msg-1',
},
], {
facetFilters: ['language:en', 'type:content'] // Filter to relevant content
});
// Handle streaming response
for await (const chunk of stream) {
console.log(chunk); // Handle each chunk of the response
}
Benefits of custom integration:
- Full control over UI/UX
- Custom authentication and session management
- Advanced filtering and search parameters for your markdown index
- Integration with existing chat systems
- Custom analytics and monitoring
📚 Learn More: For complete API documentation, authentication details, advanced examples, and more integration patterns, see the Ask AI API Reference.
Using Facet Filters with Your Markdown Index:
Since your markdown index includes attributes like lang, version, and docusaurus_tag, you can filter Ask AI's context precisely:
// Example: Filter to English documentation only
const searchParameters = {
facetFilters: ['lang:en']
};
// Example: Filter to specific version and content type
const searchParameters = {
facetFilters: ['lang:en', 'version:latest', 'type:content']
};
// Example: Use OR logic for multiple tags (from your integration examples)
const searchParameters = {
facetFilters: [
'lang:en',
[
'docusaurus_tag:default',
'docusaurus_tag:docs-default-current'
]
]
};
Conseil : Maintenez les deux index à jour au fur et à mesure que votre documentation évolue pour garantir la meilleure qualité de recherche et de réponses de l'IA.
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
Bonnes pratiques et conseils
-
Utilisez des titres clairs et cohérents dans vos fichiers Markdown pour une meilleure découvrabilité.
-
Testez votre index avec Ask AI pour vous assurer que des réponses pertinentes sont renvoyées.
-
Ajustez
maxRecordBytessi vous remarquez que les réponses sont trop larges ou trop fragmentées.- Remarque : Augmenter
maxRecordBytespeut augmenter le nombre de tokens pour les LLMs, ce qui peut affecter la taille de la fenêtre de contexte et le coût de chaque réponse d'Ask AI.
- Remarque : Augmenter
-
Maintenez votre Markdown bien structuré (utilisez des titres, listes, etc.) pour un découpage optimal.
-
Ajoutez des attributs comme
lang,versionoutagsà vos enregistrements etattributesForFacetingsi vous souhaitez filtrer ou utiliser des facettes dans votre interface de recherche ou Ask AI.
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
FAQ
Q : Pourquoi utiliser un index Markdown séparé ? R : Cela permet à Ask AI d'accéder au contenu dans un format optimisé pour les LLMs, améliorant ainsi la qualité des réponses.
Q : Puis-je utiliser cette solution avec d'autres types de contenu ? R : Oui, mais le Markdown est particulièrement adapté au découpage et à l'extraction de contexte.
Q : Que faire si j'ai des fichiers Markdown très volumineux ?
R : Diminuez la valeur de maxRecordBytes pour diviser le contenu en enregistrements plus petits et plus ciblés.
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
Pour plus de détails, consultez la documentation d'Ask AI ou contactez le support si vous avez besoin d'aide pour configurer votre Crawler.
id: examples title: Exemples et extensions description: démonstrations en direct montrant comment utiliser et étendre DocSearch au-delà des cas d'usage strictement documentaires.
Exemples de configuration du Crawler par intégration
Vous trouverez ci-dessous des exemples de configuration pour mettre en place votre index Markdown avec différentes plateformes de documentation. Chacun montre comment extraire des facettes (comme la langue, la version, les tags) et configurer le Crawler pour votre intégration spécifique :
- Non-DocSearch (Generic)
- Docusaurus
- VitePress
- Astro / Starlight
Generic Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language,
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Recommended if you add more attributes outside of objectID
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Docusaurus Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
// Extract meta tag values. These are required for Docusaurus
const language =
$('meta[name="docsearch:language"]').attr("content") || "en";
const version =
$('meta[name="docsearch:version"]').attr("content") || "latest";
const docusaurus_tag =
$('meta[name="docsearch:docusaurus_tag"]').attr("content") || "";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for Docusaurus
language, // Required for Docusaurus
version: version.split(","), // in case there are multiple versions. Required for Docusaurus
docusaurus_tag: docusaurus_tag // Required for Docusaurus
.split(",")
.map((tag) => tag.trim())
.filter(Boolean),
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang", "language", "version", "docusaurus_tag"], // Required for Docusaurus
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
VitePress Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for VitePress
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Required for VitePress
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Astro / Starlight Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for Astro/StarLight
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Required for Astro/StarLight
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Chaque exemple montre comment extraire des facettes courantes et configurer votre index Markdown pour Ask AI. Ajustez les sélecteurs et les noms des balises meta selon les besoins de votre site.