Mejorar la calidad de respuestas con indexación Markdown
Esta página fue traducida por PageTurner AI (beta). No está respaldada oficialmente por el proyecto. ¿Encontraste un error? Reportar problema →
Para ofrecer respuestas más precisas y con mayor contexto a escala, Ask AI se beneficia de contenido estructurado y limpio. Una de las formas más efectivas de lograrlo es usando un asistente de indexación basado en Markdown en tu configuración del Crawler de Algolia. Esta configuración garantiza que Ask AI acceda a registros bien formados y centrados en el contenido, algo especialmente importante en sitios de documentación grandes donde metadatos, elementos de navegación o artefactos de diseño podrían diluir la calidad de las respuestas generativas.
La configuración de indexación Markdown puede automatizarse mediante la interfaz de Crawler para la mayoría de casos. Para personalizaciones avanzadas o comprender la configuración subyacente, también existen opciones de configuración manual.
Nota: Para más ejemplos de integración (Docusaurus, VitePress, Astro/Starlight y configuraciones genéricas), consulta la sección al final de esta página.
Introducción
Para maximizar la calidad de las respuestas de Ask AI, configura tu Crawler para crear un índice dedicado a contenido Markdown. Este enfoque permite a Ask AI trabajar con registros estructurados y fragmentados obtenidos de tu documentación, soporte o cualquier material basado en Markdown, lo que resulta en respuestas significativamente más relevantes y precisas.
Puedes configurar la indexación Markdown de dos formas:
-
Configuración automatizada (recomendada): Usa la interfaz de Crawler para crear y configurar automáticamente tu índice Markdown
-
Configuración manual: Configura manualmente tu Crawler para necesidades de personalización avanzada
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Configuración automatizada de indexación Markdown (recomendada)
La forma más sencilla de configurar la indexación Markdown es mediante la interfaz del Crawler, que crea y configura automáticamente un índice Markdown optimizado para Ask AI.
Paso 1: Acceder a la indexación Markdown en la configuración de Crawler
-
Navega al panel de control de tu Crawler
-
Ve a Configuración → pestaña Markdown para LLMs
-
Verás la sección de Indexación Markdown donde puedes crear un índice dedicado
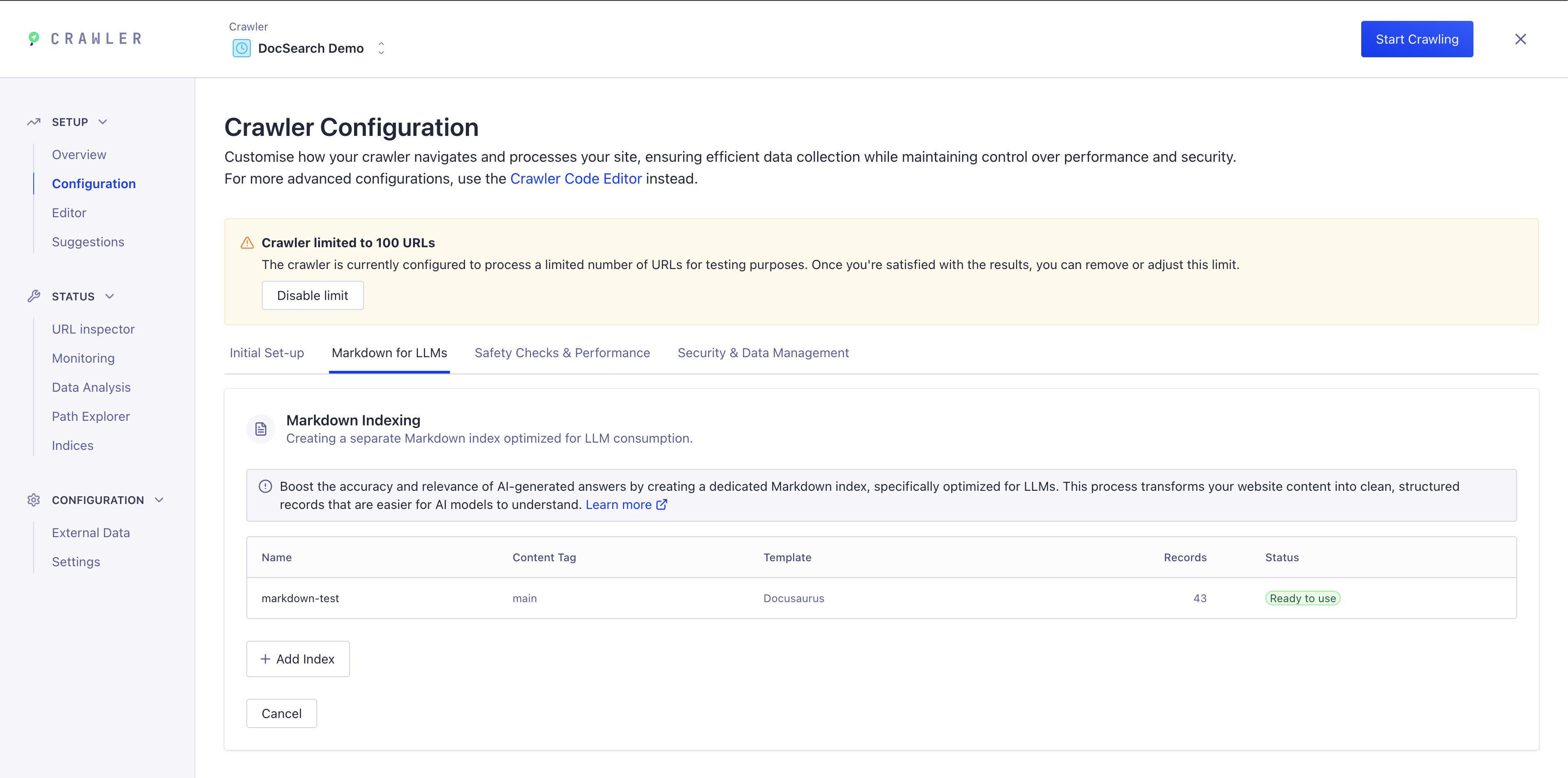
Paso 2: Agregar un nuevo índice Markdown
-
Haz clic en "+ Agregar índice" para crear un nuevo índice Markdown
-
Fill in the required fields:
- Index Name: Enter a descriptive name (e.g.,
my-docs-markdown) - Content Tag: Specify the HTML content selector (typically
main) - Template: Choose the template that matches your documentation framework:
- Docusaurus - For Docusaurus sites
- VitePress - For VitePress sites
- Astro/Starlight - For Astro/Starlight sites
- Non-DocSearch (Generic) - For custom sites or other frameworks
- Index Name: Enter a descriptive name (e.g.,
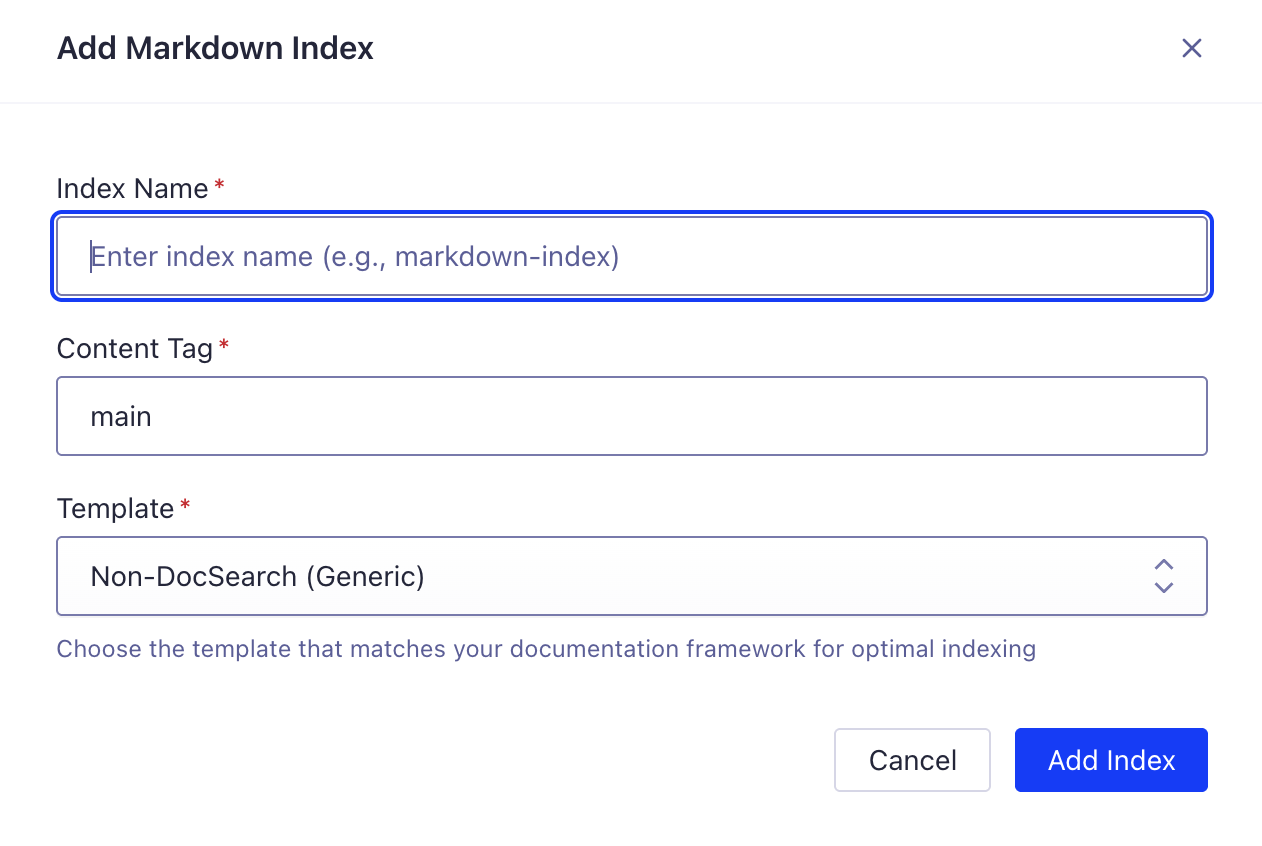
- Haz clic en "Agregar índice" para crearlo
El Crawler configurará automáticamente los ajustes óptimos para tu plantilla seleccionada, incluyendo:
-
Extracción y fragmentación adecuada de registros
-
Extracción de metadatos específicos del framework (idioma, versión, etiquetas)
-
Ajustes de índice optimizados para Ask AI
Paso 3: Ejecutar el Crawler
Una vez configurado tu índice Markdown:
-
Haz clic en "Iniciar rastreo" para comenzar a indexar tu contenido
-
Monitorea el progreso del rastreo en el panel
-
Tu nuevo índice Markdown se poblará con registros limpios y estructurados optimizados para Ask AI
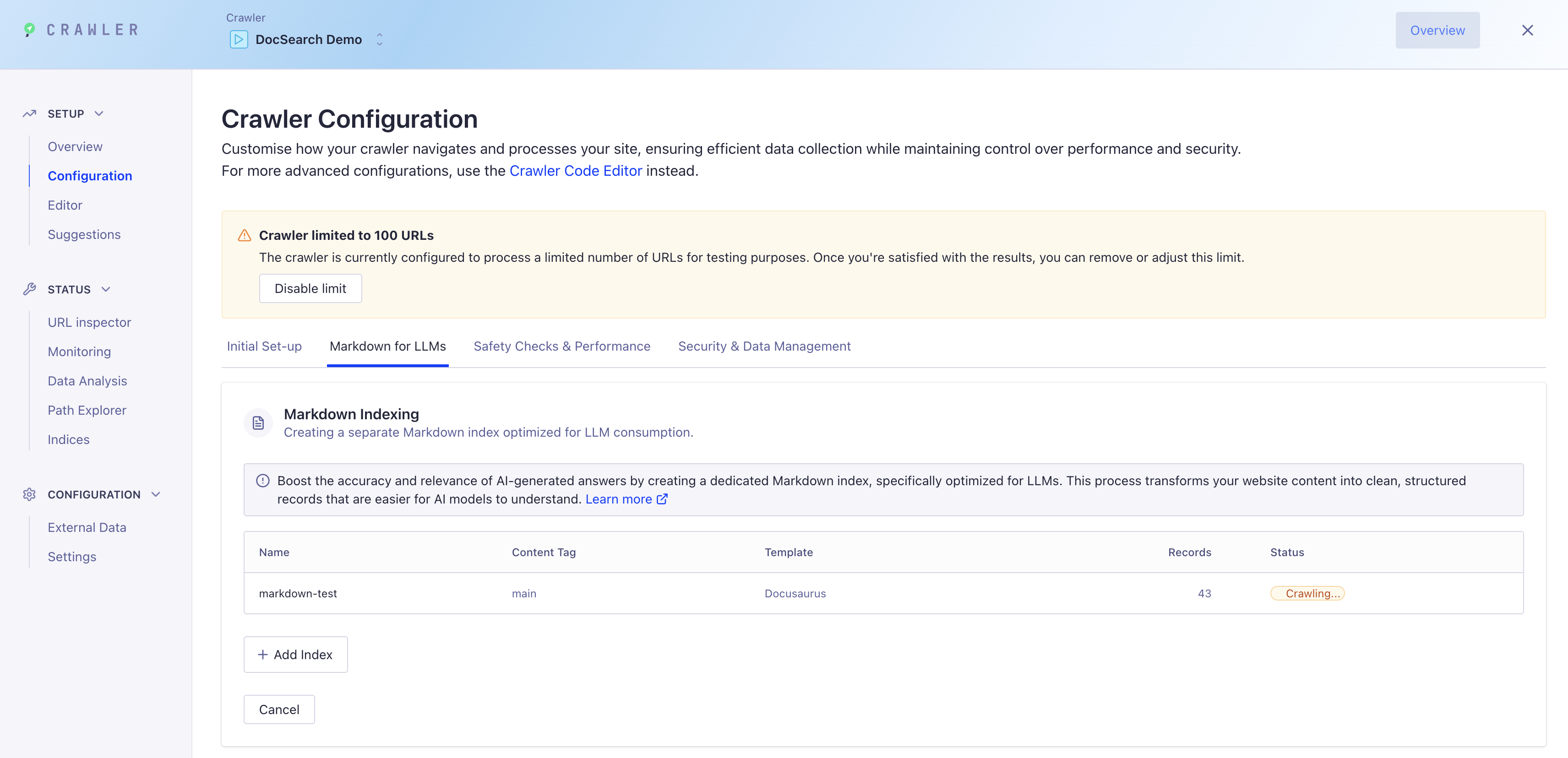
Paso 4: Integrar con Ask AI
Tras completar el rastreo, configura DocSearch para usar tu nuevo índice Markdown en las respuestas de Ask AI. Consulta la sección de Integración más abajo para instrucciones detalladas.
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Configuración manual (avanzada)
Para usuarios que necesitan personalización avanzada o quieren entender la configuración subyacente, puedes configurar manualmente la indexación de markdown modificando directamente la configuración de tu Crawler.
Paso 1: Actualiza tu configuración existente del Crawler de DocSearch
- En tu configuración del Crawler, añade lo siguiente a tu array
actions: [ ... ]:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language,
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
- Luego, añade lo siguiente a tu objeto
initialIndexSettings: { ... }:
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"],
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Paso 2: Ejecuta el crawler de DocSearch para crear un nuevo índice optimizado para Ask AI
Tras actualizar la configuración de tu Crawler:
-
Publica tu configuración en el panel de control de Algolia Crawler para guardarla y activarla.
-
Ejecuta el Crawler para indexar tu contenido de markdown y crear el nuevo índice.
El Crawler procesará tu contenido usando el asistente de extracción Markdown y poblará tu nuevo índice con registros limpios y estructurados optimizados para Ask AI.
Consejo: Supervisa el progreso del rastreo en tu panel para asegurarte de que todas las páginas se procesan correctamente. Puedes ver los registros indexados en tu índice de Algolia para verificar la estructura y el contenido.
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Integra tu nuevo índice con Ask AI
Una vez que tu Crawler haya creado tu índice optimizado, puedes integrarlo con Ask AI de dos formas: usando DocSearch (recomendado para la mayoría de usuarios) o creando una integración personalizada con la API de Ask AI.
- DocSearch Integration
- Custom API Integration
Using DocSearch
Configure DocSearch to use both your main keyword index and your markdown index for Ask AI:
- JavaScript
- React
docsearch({
indexName: 'YOUR_INDEX_NAME', // Main DocSearch keyword index
apiKey: 'YOUR_SEARCH_API_KEY',
appId: 'YOUR_APP_ID',
askAi: {
indexName: 'YOUR_INDEX_NAME-markdown', // Markdown index for Ask AI
apiKey: 'YOUR_SEARCH_API_KEY', // (or a different key if needed)
appId: 'YOUR_APP_ID',
assistantId: 'YOUR_ALGOLIA_ASSISTANT_ID',
searchParameters: {
facetFilters: ['language:en'], // Optional: filter to specific language/version
},
},
});
<DocSearch
indexName="YOUR_INDEX_NAME" // Main DocSearch keyword index
apiKey="YOUR_SEARCH_API_KEY"
appId="YOUR_APP_ID"
askAi={{
indexName: 'YOUR_INDEX_NAME-markdown', // Markdown index for Ask AI
apiKey: 'YOUR_SEARCH_API_KEY',
appId: 'YOUR_APP_ID',
assistantId: 'YOUR_ALGOLIA_ASSISTANT_ID',
searchParameters: {
facetFilters: ['language:en'], // Optional: filter to specific language/version
},
}}
/>
indexName: Your main DocSearch index for keyword search.askAi.indexName: The markdown index you created for Ask AI context.assistantId: The ID of your configured Ask AI assistant.searchParameters.facetFilters: Optional filters to limit Ask AI context (useful for multi-language sites).
Custom API Integration
We highly recommend using the DocSearch package for most use cases. Custom implementations using the Ask AI API directly are not fully supported to the same extent as the DocSearch package, and may require additional development effort for features like error handling, authentication, and UI components.
Build your own chat interface using the Ask AI API. This gives you full control over the user experience and allows for advanced customizations.
class CustomAskAI {
constructor({ appId, apiKey, indexName, assistantId }) {
this.appId = appId;
this.apiKey = apiKey;
this.indexName = indexName; // Your markdown index
this.assistantId = assistantId;
this.baseUrl = 'https://askai.algolia.com';
}
async getToken() {
const response = await fetch(`${this.baseUrl}/chat/token`, {
method: 'POST',
headers: {
'X-Algolia-Assistant-Id': this.assistantId,
},
});
const data = await response.json();
return data.token;
}
async sendMessage(conversationId, messages, searchParameters = {}) {
const token = await this.getToken();
const response = await fetch(`${this.baseUrl}/chat`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Algolia-Application-Id': this.appId,
'X-Algolia-API-Key': this.apiKey,
'X-Algolia-Index-Name': this.indexName, // Use your markdown index
'X-Algolia-Assistant-Id': this.assistantId,
'Authorization': token,
},
body: JSON.stringify({
id: conversationId,
messages,
...(Object.keys(searchParameters).length > 0 && { searchParameters }),
}),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
// Handle streaming response
const reader = response.body.getReader();
const decoder = new TextDecoder();
return {
async *[Symbol.asyncIterator]() {
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
if (chunk.trim()) {
yield chunk;
}
}
} finally {
reader.releaseLock();
}
}
};
}
}
// Usage
const askAI = new CustomAskAI({
appId: 'YOUR_APP_ID',
apiKey: 'YOUR_API_KEY',
indexName: 'YOUR_INDEX_NAME-markdown', // Your markdown index
assistantId: 'YOUR_ASSISTANT_ID',
});
// Send a message with facet filters for your markdown index
const stream = await askAI.sendMessage('conversation-1', [
{
role: 'user',
content: 'How do I configure my API?',
id: 'msg-1',
},
], {
facetFilters: ['language:en', 'type:content'] // Filter to relevant content
});
// Handle streaming response
for await (const chunk of stream) {
console.log(chunk); // Handle each chunk of the response
}
Benefits of custom integration:
- Full control over UI/UX
- Custom authentication and session management
- Advanced filtering and search parameters for your markdown index
- Integration with existing chat systems
- Custom analytics and monitoring
📚 Learn More: For complete API documentation, authentication details, advanced examples, and more integration patterns, see the Ask AI API Reference.
Using Facet Filters with Your Markdown Index:
Since your markdown index includes attributes like lang, version, and docusaurus_tag, you can filter Ask AI's context precisely:
// Example: Filter to English documentation only
const searchParameters = {
facetFilters: ['lang:en']
};
// Example: Filter to specific version and content type
const searchParameters = {
facetFilters: ['lang:en', 'version:latest', 'type:content']
};
// Example: Use OR logic for multiple tags (from your integration examples)
const searchParameters = {
facetFilters: [
'lang:en',
[
'docusaurus_tag:default',
'docusaurus_tag:docs-default-current'
]
]
};
Consejo: Mantén ambos índices actualizados a medida que evoluciona tu documentación para garantizar la mejor calidad en búsquedas y respuestas de IA.
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Mejores prácticas y consejos
-
Usa títulos claros y consistentes en tus archivos markdown para mejorar la buscabilidad.
-
Prueba tu índice con Ask AI para garantizar que devuelve respuestas relevantes.
-
Ajusta
maxRecordBytessi notas que las respuestas son demasiado amplias o fragmentadas.- Nota: Aumentar
maxRecordBytespuede incrementar el recuento de tokens para LLMs, lo que podría afectar el tamaño de la ventana de contexto y el costo de cada respuesta de Ask AI.
- Nota: Aumentar
-
Mantén tu markdown bien estructurado (usa encabezados, listas, etc.) para una fragmentación óptima.
-
Añade atributos como
lang,versionotagsa tus registros yattributesForFacetingsi deseas filtrar o usar facetas en tu interfaz de búsqueda o Ask AI.
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Preguntas frecuentes
P: ¿Por qué usar un índice Markdown separado?
R: Permite a Ask AI acceder a contenido en un formato optimizado para LLMs, mejorando la calidad de las respuestas.
P: ¿Puedo usarlo con otros tipos de contenido?
R: Sí, pero markdown es especialmente adecuado para fragmentación y extracción de contexto.
P: ¿Qué pasa con archivos markdown muy grandes?
R: Reduce el valor de maxRecordBytes para dividir el contenido en registros más pequeños y enfocados.
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Para más detalles, consulta la documentación de Ask AI o contacta a soporte si necesitas ayuda configurando tu Crawler.
id: examples title: Ejemplos y extensiones description: Demostraciones en vivo que muestran cómo usar y extender DocSearch más allá de casos de uso exclusivos de documentación.
Ejemplos de configuración del Crawler por integración
A continuación se muestran configuraciones de ejemplo para configurar tu índice de markdown con diferentes plataformas de documentación. Cada una muestra cómo extraer facetas (como idioma, versión, etiquetas) y configurar el Crawler para tu integración específica:
- Non-DocSearch (Generic)
- Docusaurus
- VitePress
- Astro / Starlight
Generic Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language,
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Recommended if you add more attributes outside of objectID
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Docusaurus Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
// Extract meta tag values. These are required for Docusaurus
const language =
$('meta[name="docsearch:language"]').attr("content") || "en";
const version =
$('meta[name="docsearch:version"]').attr("content") || "latest";
const docusaurus_tag =
$('meta[name="docsearch:docusaurus_tag"]').attr("content") || "";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for Docusaurus
language, // Required for Docusaurus
version: version.split(","), // in case there are multiple versions. Required for Docusaurus
docusaurus_tag: docusaurus_tag // Required for Docusaurus
.split(",")
.map((tag) => tag.trim())
.filter(Boolean),
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang", "language", "version", "docusaurus_tag"], // Required for Docusaurus
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
VitePress Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for VitePress
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Required for VitePress
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Astro / Starlight Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for Astro/StarLight
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Required for Astro/StarLight
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Cada ejemplo muestra cómo extraer facetas comunes y configurar tu índice Markdown para Ask AI. Ajusta los selectores y nombres de metaetiquetas según necesites para tu sitio.