Comment construisons-nous un index DocSearch ?
Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →
Dans cette section, vous découvrirez comment nous construisons un index DocSearch à partir de votre page.
Tout commence avec votre page

Nous extrayons la charge utile selon vos selectors

Nous nous concentrons sur les informations mises en évidence en fonction de vos selectors.
Nous parcourons le flux HTML pour construire la charge utile
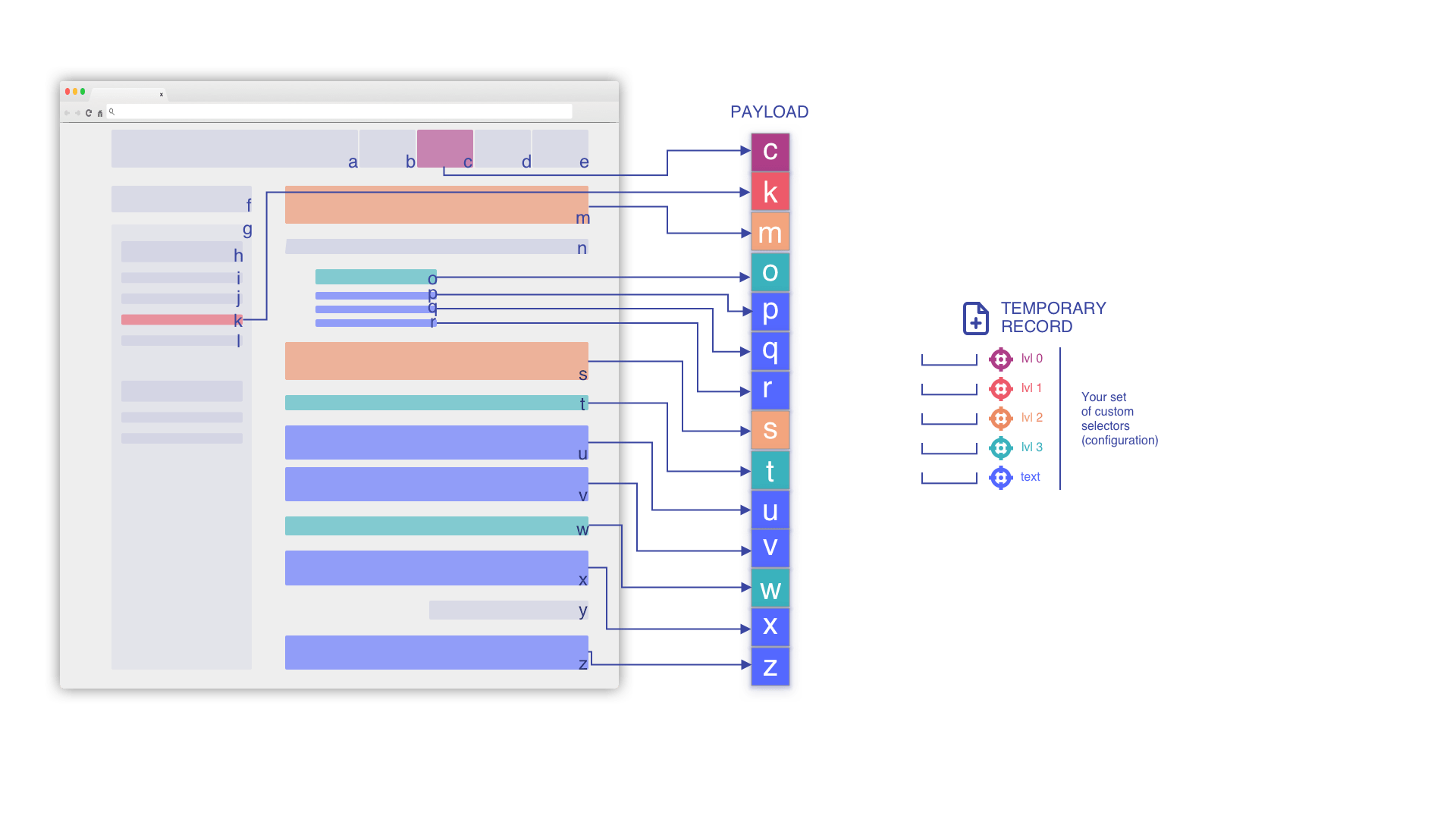
Cette charge utile constituera la seule donnée extraite de votre page.
Nous parcourons la charge utile et commençons à pousser des enregistrements
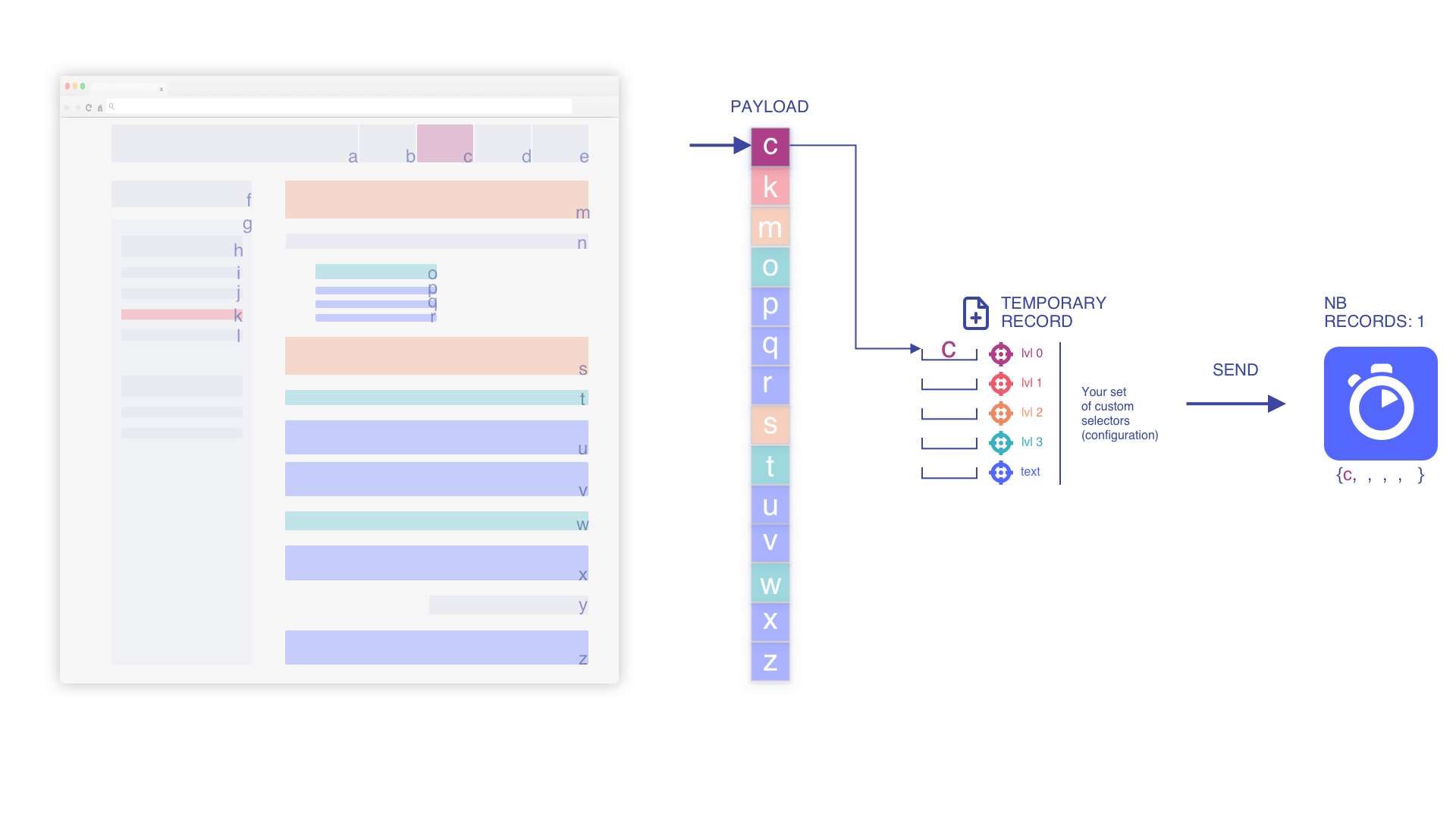
Nous indexons l'enregistrement temporaire lors de l'ajout d'un élément (si min_indexed_level vaut 0)
Nous empilons les éléments selon l'enregistrement temporaire actuel
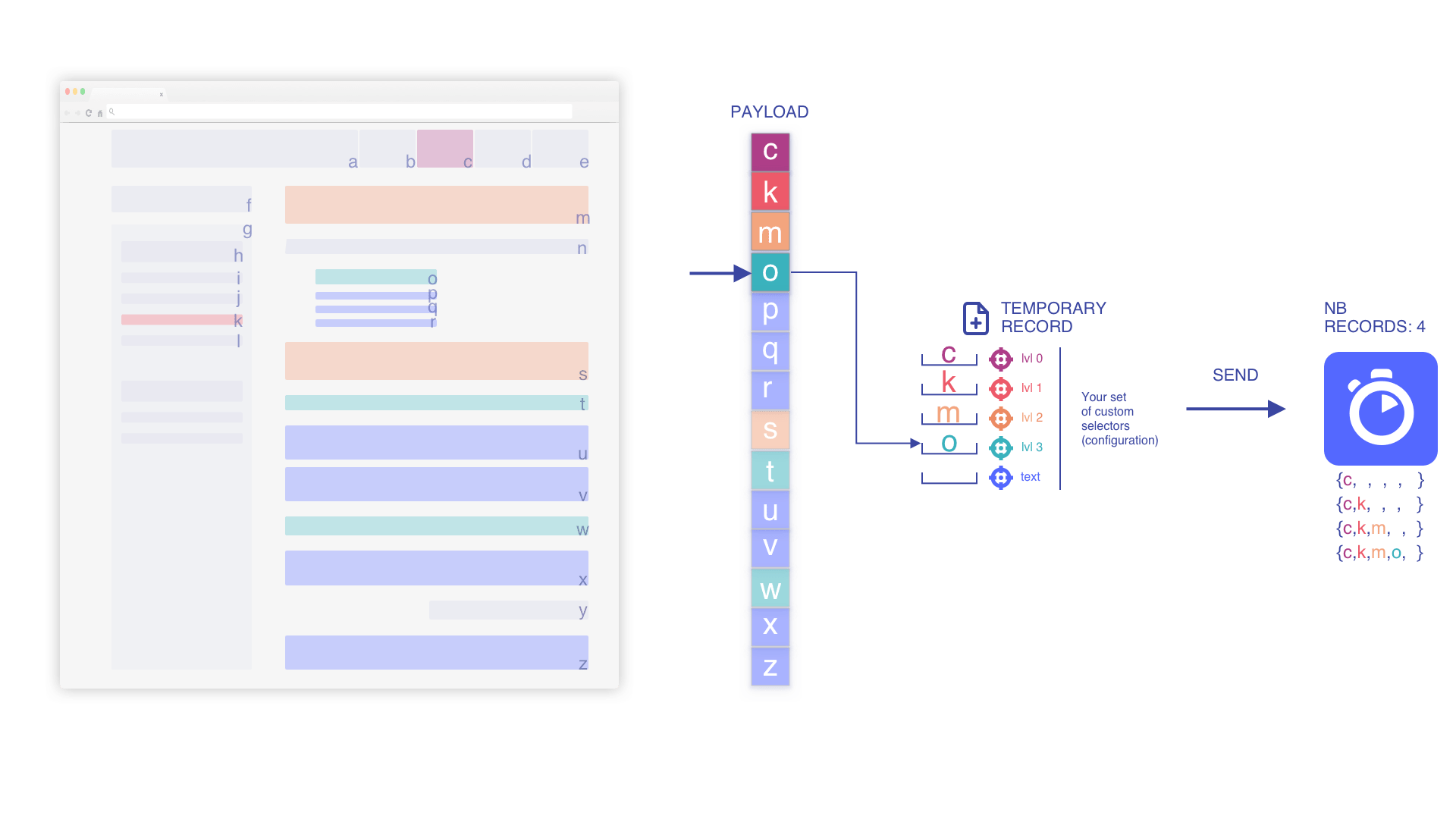
En fonction de la position dans le flux, nous imbriquons les éléments autant que possible pour préserver le contexte et augmenter la pertinence.
Nous itérons jusqu'à trouver un élément text
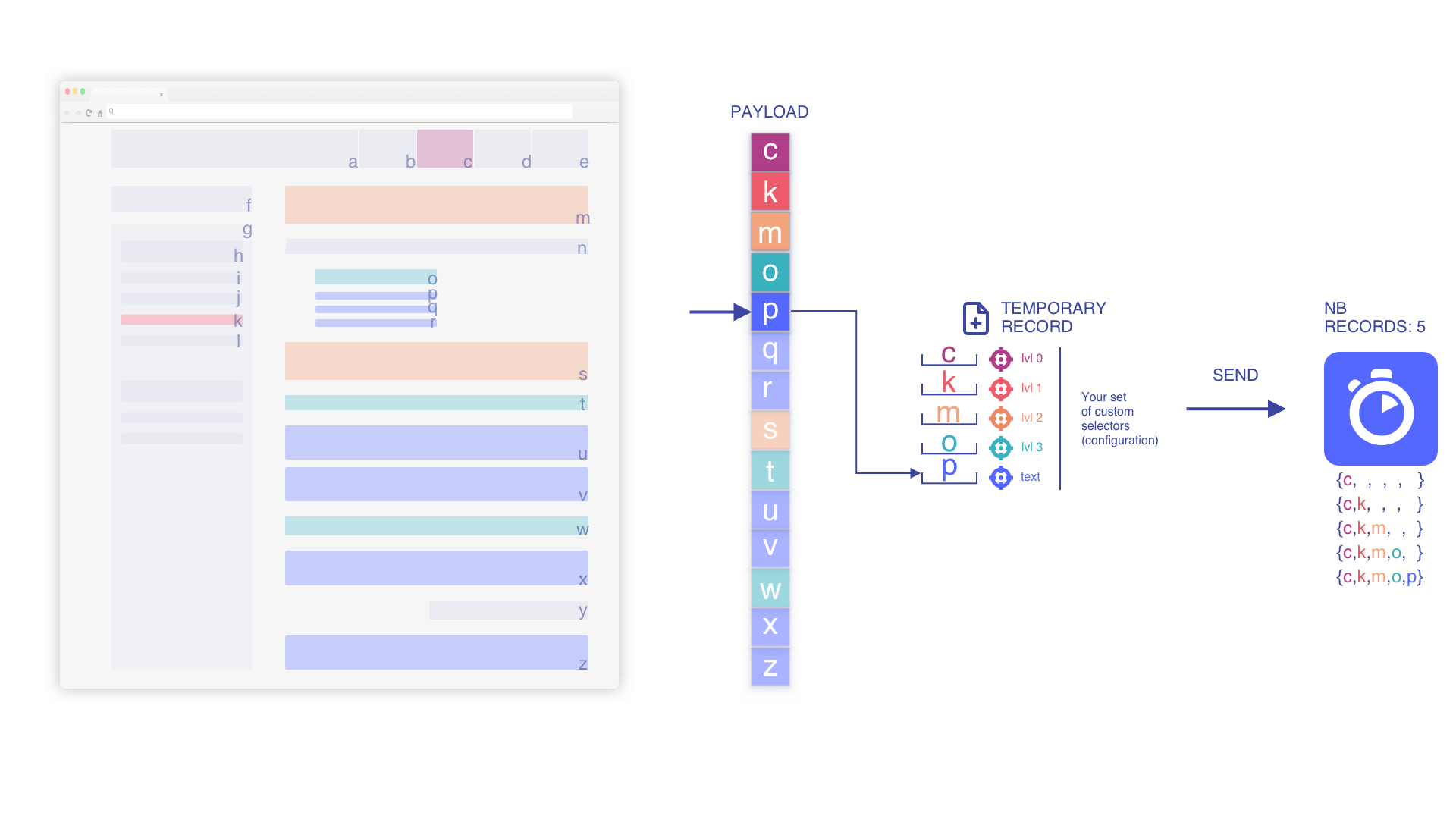
Nous remplaçons l'élément text lors de la découverte d'un plus récent
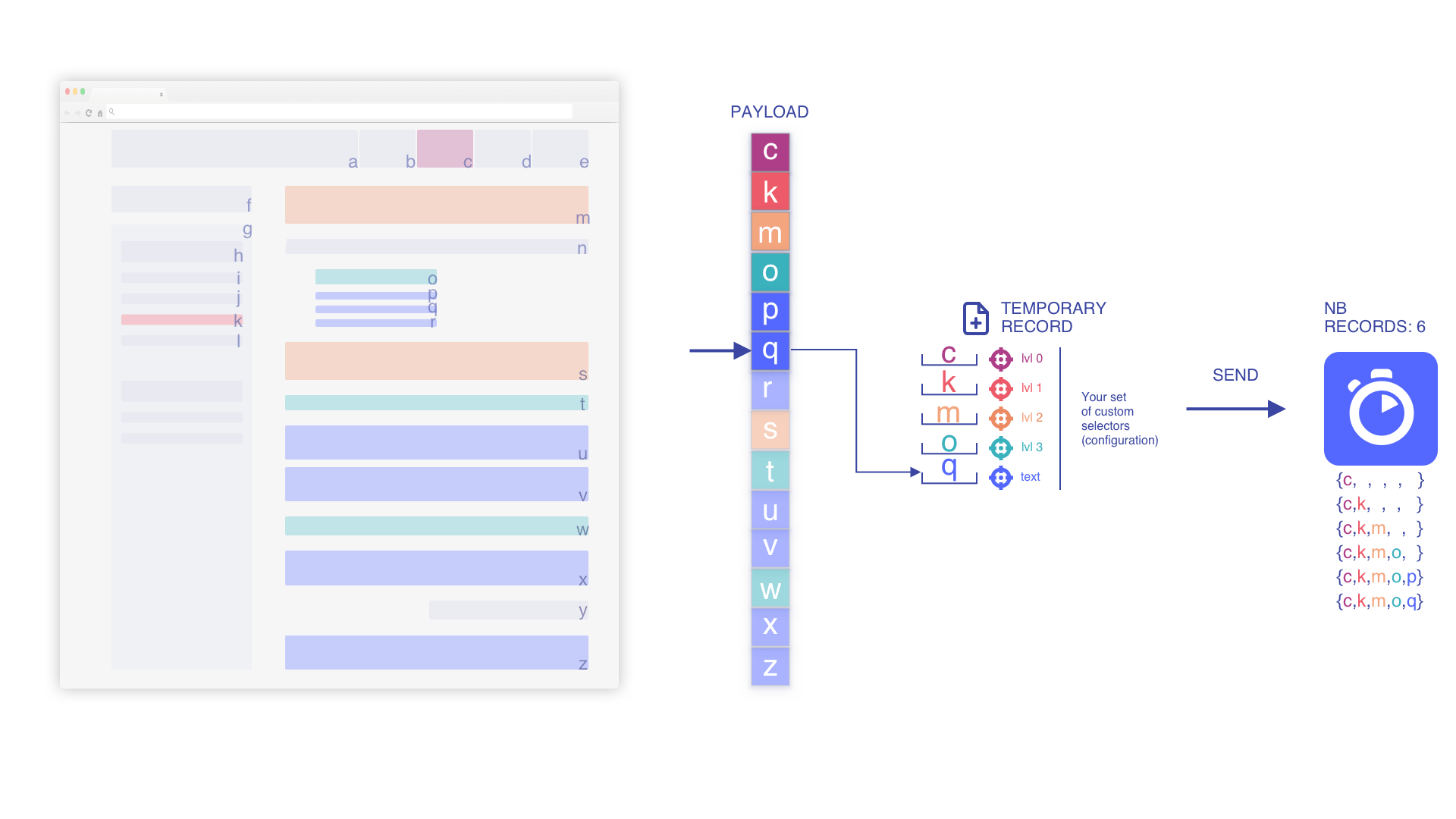
Nous supprimons les éléments profonds mis de côté lors de l'ajout d'un niveau supérieur
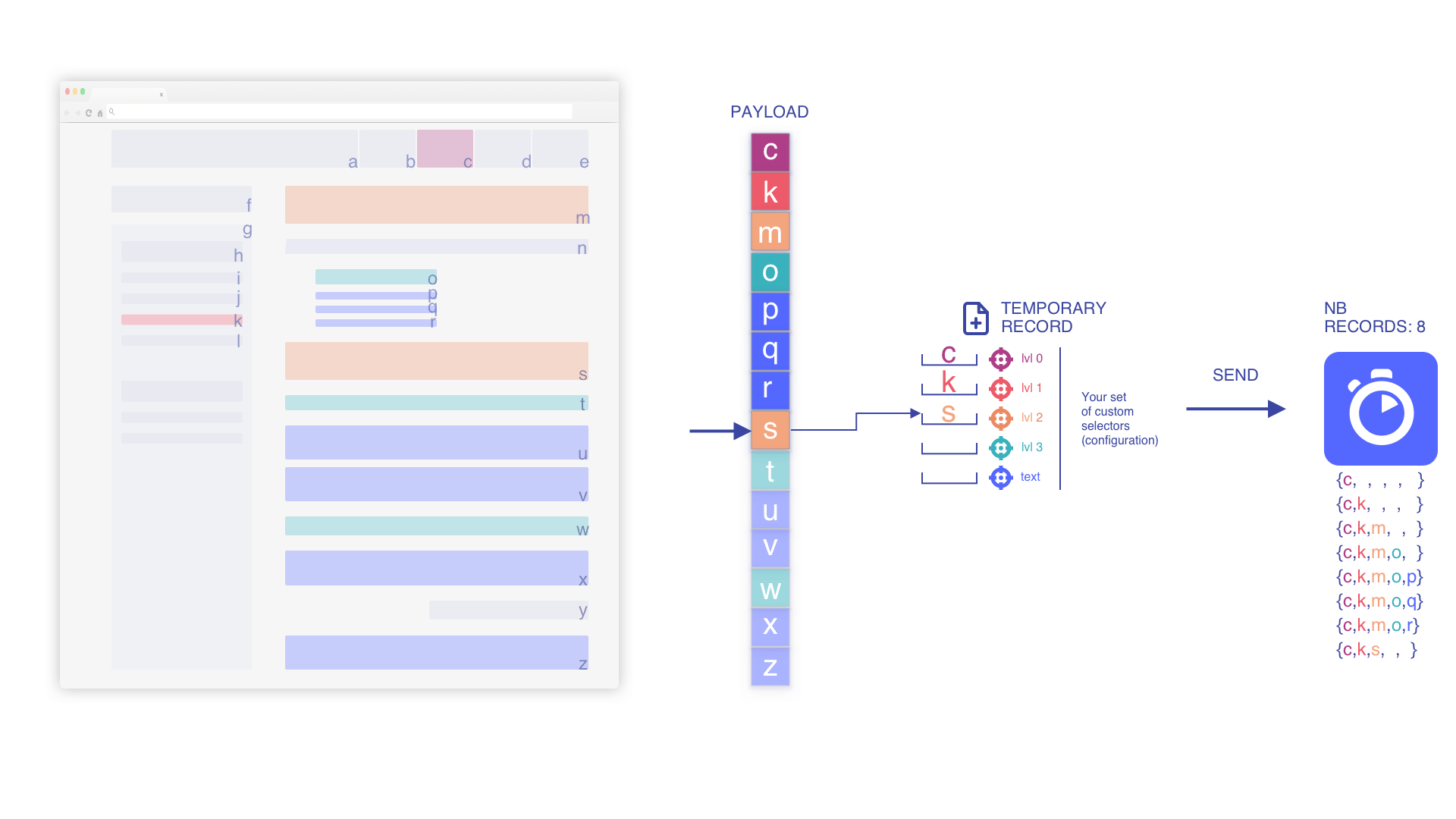
Les informations contextuelles et la hiérarchie doivent être mises à jour dès qu'un nouveau niveau est rencontré. Cette opération est nécessaire car elle signale une nouvelle sous-section sans lien avec la précédente.
Si vous avez besoin d'informations complémentaires, contactez-nous sur Discord ou informez notre équipe de support.