Exécutez votre propre instance
Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →
Si vous souhaitez mettre à jour vos résultats avec plus de contrôle, si vous ne respectez pas notre liste de vérification, ou si votre site est derrière un pare-feu, vous pourriez vouloir exécuter vous-même le crawler.
L'entière base de code de DocSearch est open source, et nous l'empaquetons en image Docker pour faciliter son utilisation.
Configurer votre environnement
Vous devrez définir votre ID d'application Algolia et votre clé API admin comme variables d'environnement. Si vous n'avez pas de compte Algolia, vous devez en créer un.
-
APPLICATION_IDconfiguré avec votre ID d'application Algolia -
API_KEYconfigurée avec votre clé API. Assurez-vous d'utiliser une clé API avec un accès en écriture à votre index. Elle nécessite les ACLaddObject,editSettingsetdeleteIndex.
Pour plus de commodité, vous pouvez créer un fichier .env à la racine du dépôt.
APPLICATION_ID=YOUR_APP_ID
API_KEY=YOUR_API_KEY
Exécuter le crawl depuis l'image Docker
Vous pouvez lancer un crawl depuis l'image Docker empaquetée pour explorer votre site. Vous devrez installer jq, un processeur JSON léger en ligne de commande
Vous devez ensuite démarrer le crawl selon votre configuration. Consultez la documentation dédiée à la configuration.
docker run -it --env-file=.env -e "CONFIG=$(cat /path/to/your/config.json | jq -r tostring)" algolia/docsearch-scraper
Une fois le scraping terminé, vous pouvez passer directement à l'étape d'intégration.
Exécuter le crawler depuis la base de code
Installation
Le scraper est un outil Python basé sur scrapy. Nous recommandons d'utiliser pipenv pour installer l'environnement Python.
-
pipenv install -
pipenv shell
Si vous prévoyez d'utiliser l'émulation navigateur (js_render défini sur true), vous devez suivre cette étape supplémentaire. Sinon, vous pouvez l'ignorer.
Installation du ChromeDriver
Certains sites nécessitent du JavaScript pour leur rendu. Notre crawler utilise une émulation Chrome headless. Vous devrez configurer un ChromeDriver.
-
Installez le driver correspondant à votre OS et votre version de Chrome. Nous recommandons la dernière version.
-
Définissez la variable d'environnement
CHROMEDRIVER_PATHdans votre fichier.env. Ce chemin doit pointer vers le driver extrait après téléchargement.
Vous êtes prêt.
Exécution du crawler
L'exécution de pipenv shell activera votre environnement virtuel. Depuis celui-ci, vous pouvez lancer un crawl avec la commande suivante :
$ ./docsearch run /path/to/your/config.json
Ou depuis l'image Docker :
$ ./docsearch docker:run /path/to/your/config.json
Ceci démarrera le crawl. Il extrait le contenu des pages analysées et envoie les enregistrements construits vers Algolia.
Créer une nouvelle configuration
Pour créer une configuration, exécutez ./docsearch bootstrap. Un prompt vous demandera des informations et créera une configuration JSON de base.
$ ./docsearch bootstrap
# Enter your documentation url
start url: http://www.example.com/docs/
# Pick another name, or press enter
index_name is example [enter to confirm]: <Enter>
=================
{
"index_name": "example",
"start_urls": [
"http://www.example.com/docs/"
],
"stop_urls": [],
"selectors": {
"lvl0": "FIXME h1",
"lvl1": "FIXME h2",
"lvl2": "FIXME h3",
"lvl3": "FIXME h4",
"lvl4": "FIXME h5",
"lvl5": "FIXME h6",
"text": "FIXME p, FIXME li"
}
}
=================
Créez un fichier nommé example.json à partir de ce texte, nous l'utiliserons plus tard pour démarrer le crawl. Vous pouvez consulter la liste des configurations actives.
Tester vos résultats
Testez vos résultats avec ./docsearch playground. Ceci ouvrira une page web avec un champ de recherche pour tester en direct les résultats indexés.
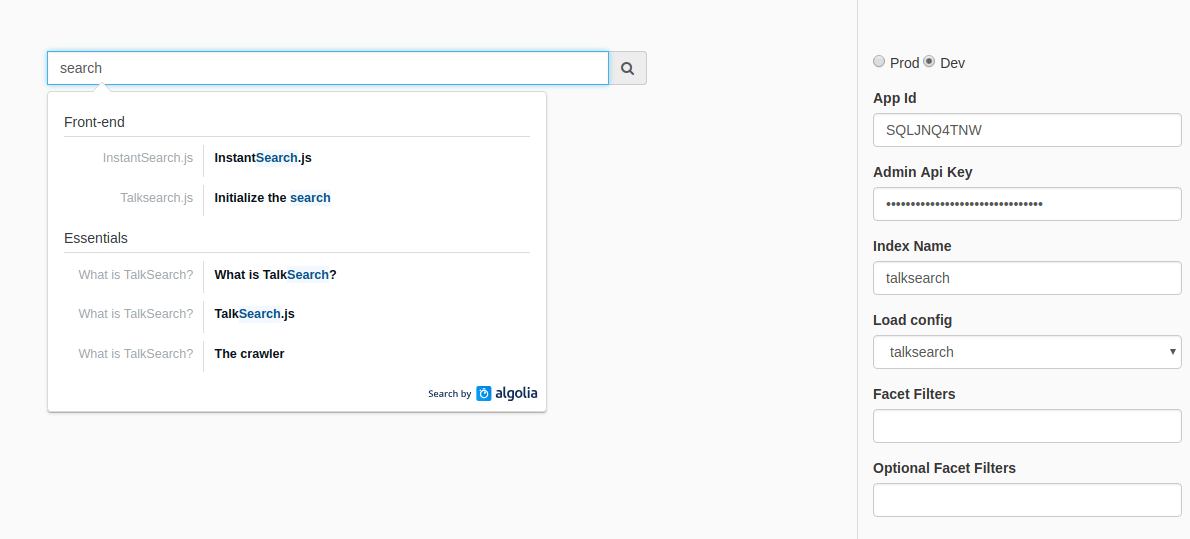
Notez que si la commande échoue (possible sur des machines non-Mac), vous pouvez obtenir le même résultat en lançant un serveur local dans le sous-répertoire ./playground.`
Intégration
Une fois votre configuration satisfaisante, vous pouvez intégrer le menu déroulant dans votre site en suivant les instructions ici.
La différence est que vous devrez ajouter la clé appId à votre instance docsearch(). N'oubliez pas non plus d'utiliser une clé API de recherche ici (et non la clé API en écriture utilisée pour le crawl).
docsearch({
appId: '<APP_ID>', // Add your own Application ID
apiKey: '<API_KEY>', // Set it to your own *search* API key
[…] // Other parameters are the same
});
Assistance
Exécutez ./docsearch sans argument pour voir la liste des commandes disponibles.
Notez que nous utilisons cet outil en ligne de commande en interne chez Algolia pour la version hébergée gratuite, donc certaines commandes listées pourraient ne pas vous concerner.