DocSearch インデックスの構築方法
非公式ベータ版翻訳
このページは PageTurner AI で翻訳されました(ベータ版)。プロジェクト公式の承認はありません。 エラーを見つけましたか? 問題を報告 →
このセクションでは、ページからDocSearchインデックスを構築する方法について説明します。
すべてはあなたのページから始まります

設定した selectors に基づいてペイロードを抽出

セレクタ設定に応じて、ハイライトされた情報に焦点を当てます。
HTMLフロ�ーを反復処理してペイロードを構築
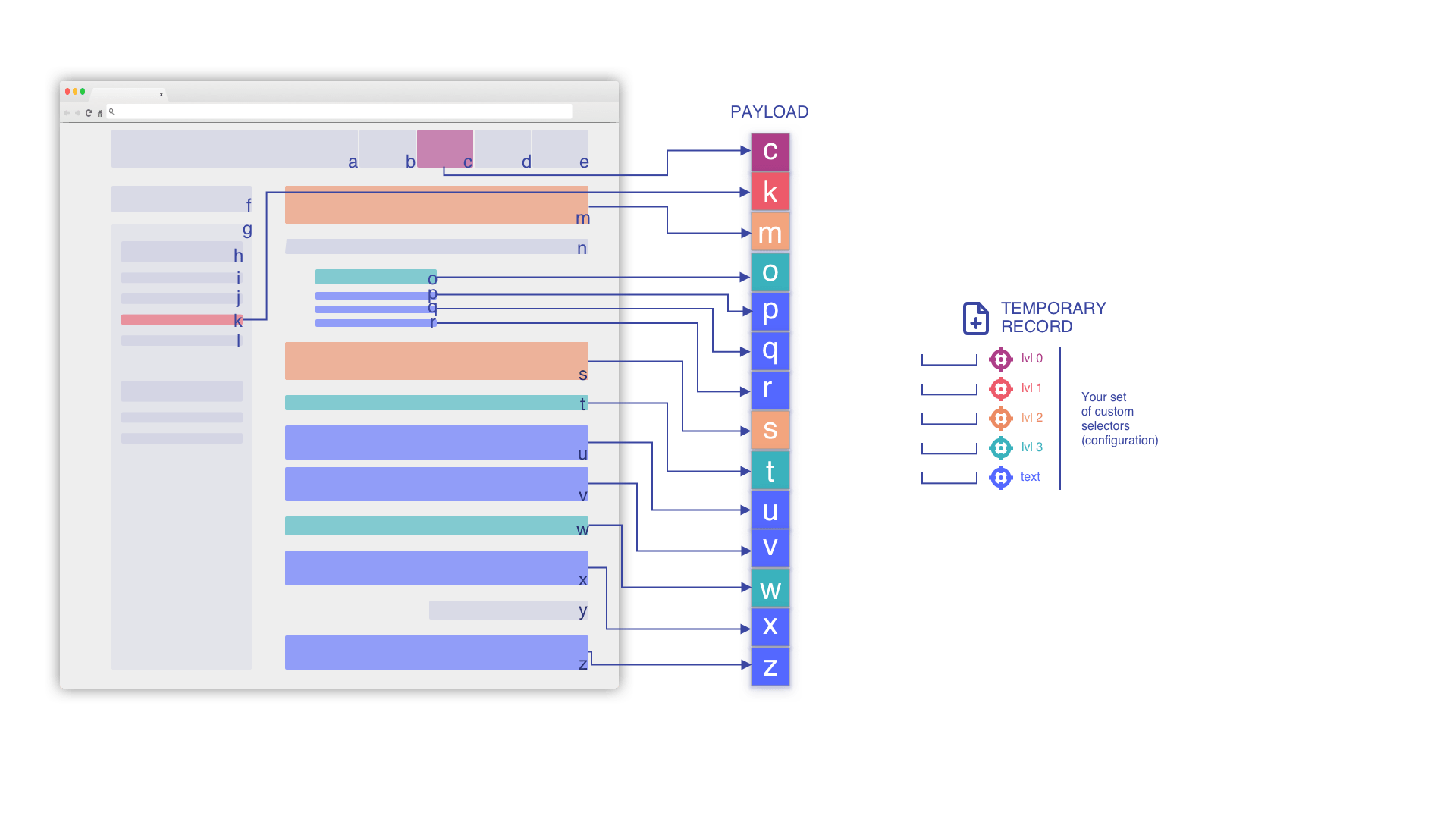
このペイロードはページから抽出される唯一のデータです。
ペイロードを反復処理しレコードのプッシュを開始
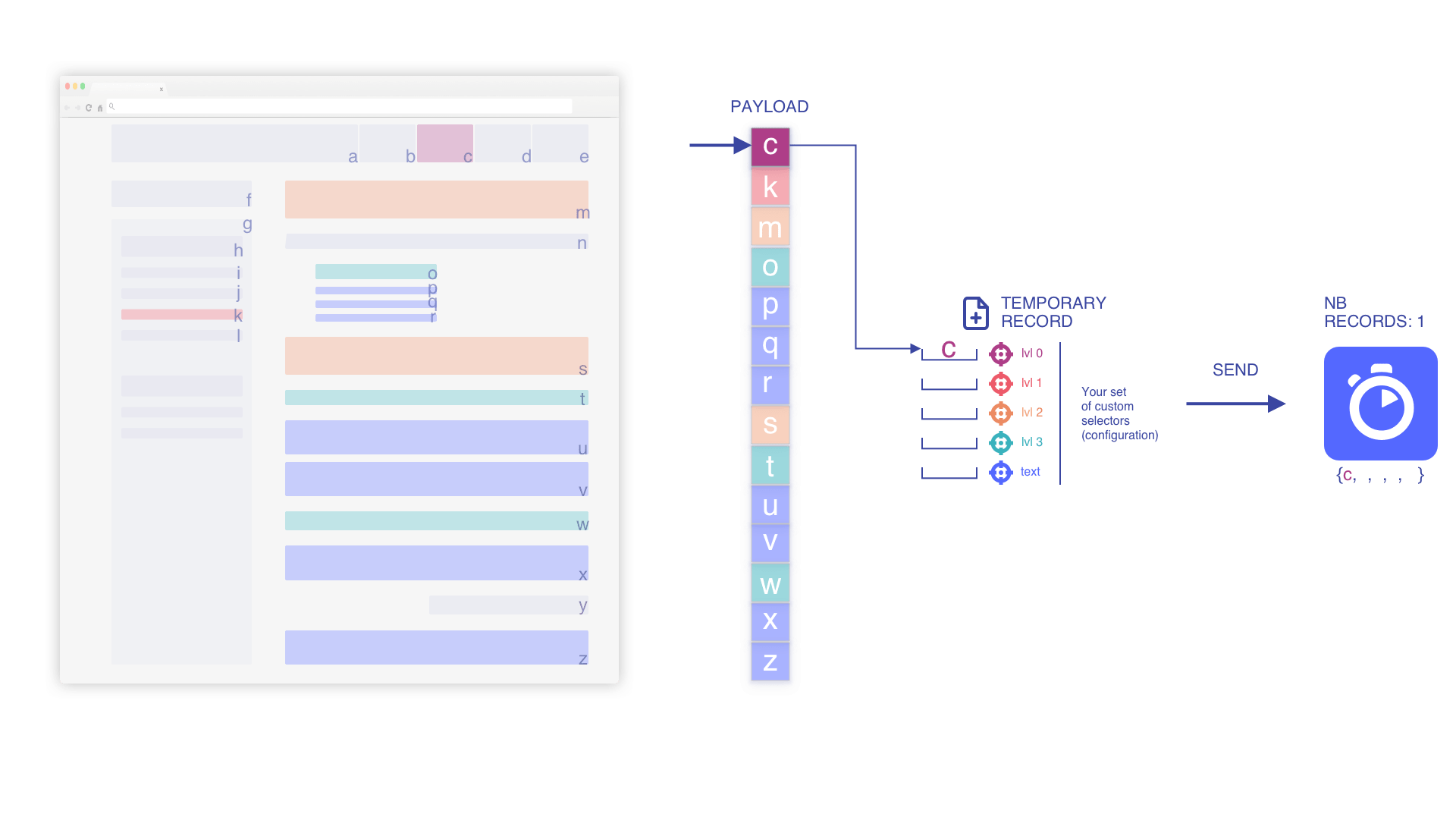
要素を追加する際に一時レコードをインデックス化します(min_indexed_level が 0 の場合)
現在の一時レコードに基づいて要素を積み上げ
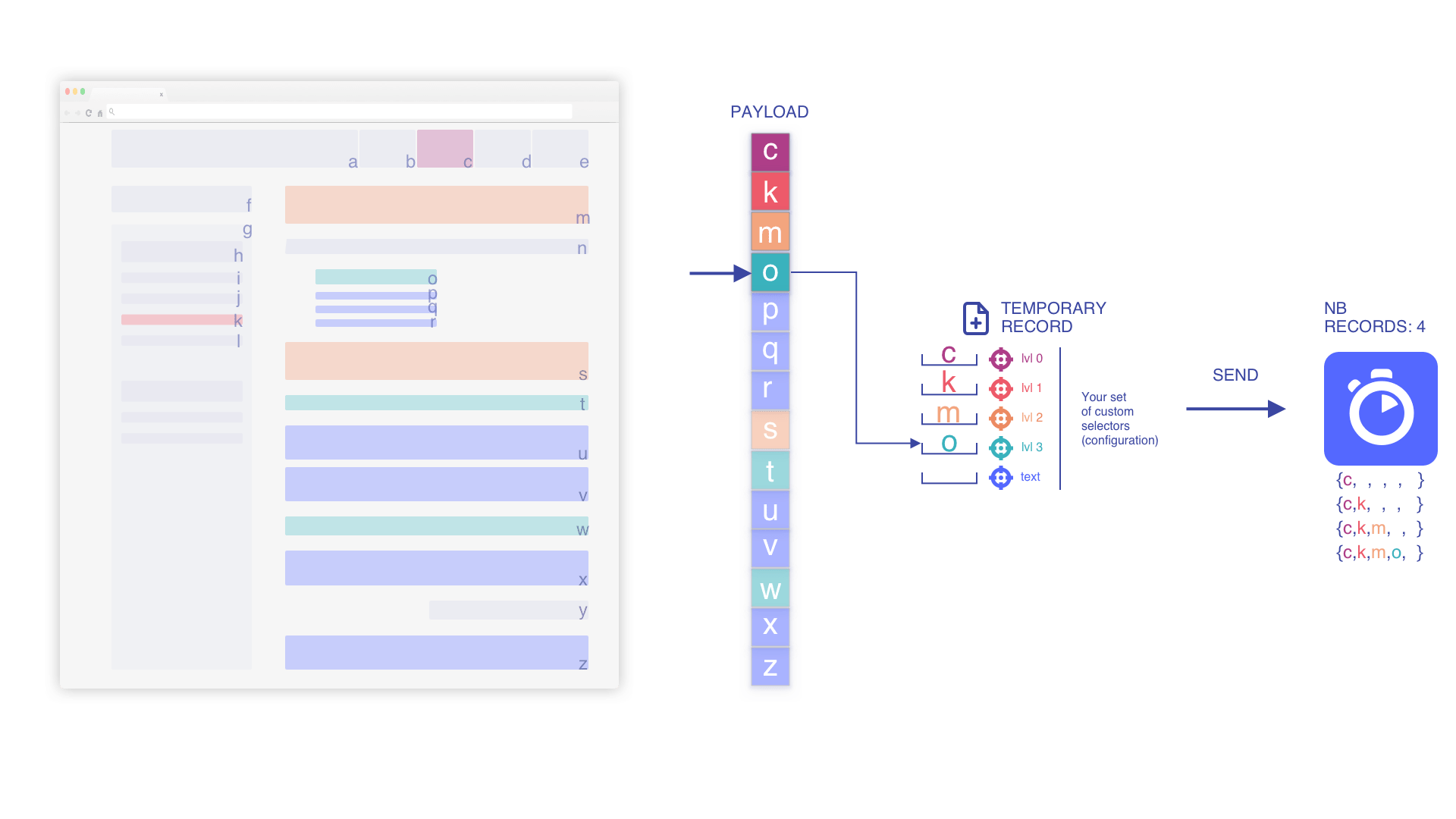
フロー内の位置に基づき、コンテキストを保持して関連性を高めるため、可能な限り要素をネストします。
text 要素に一致するまで反復処理を継続
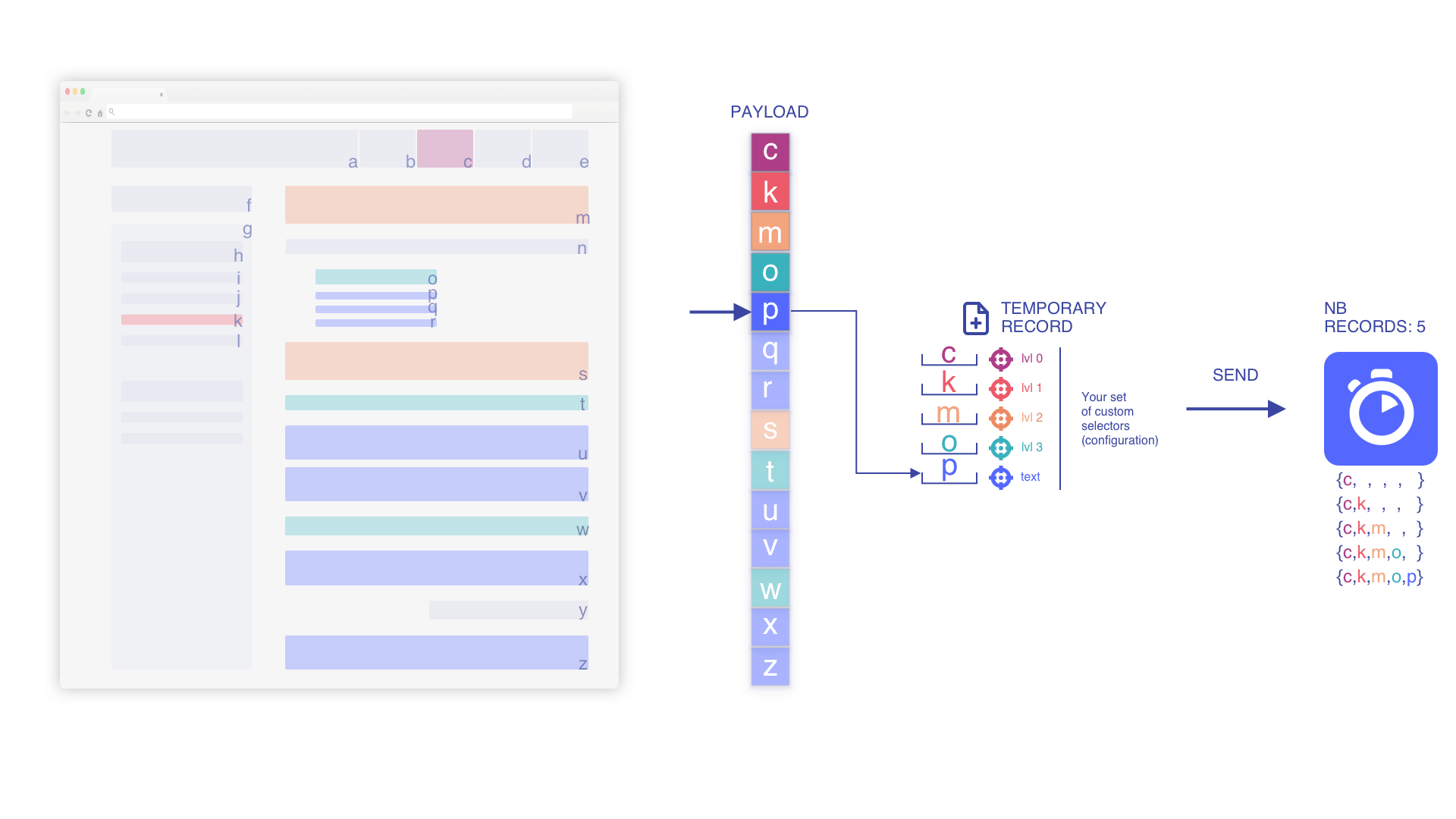
新しいテキスト要素が見つかった場合に上書き
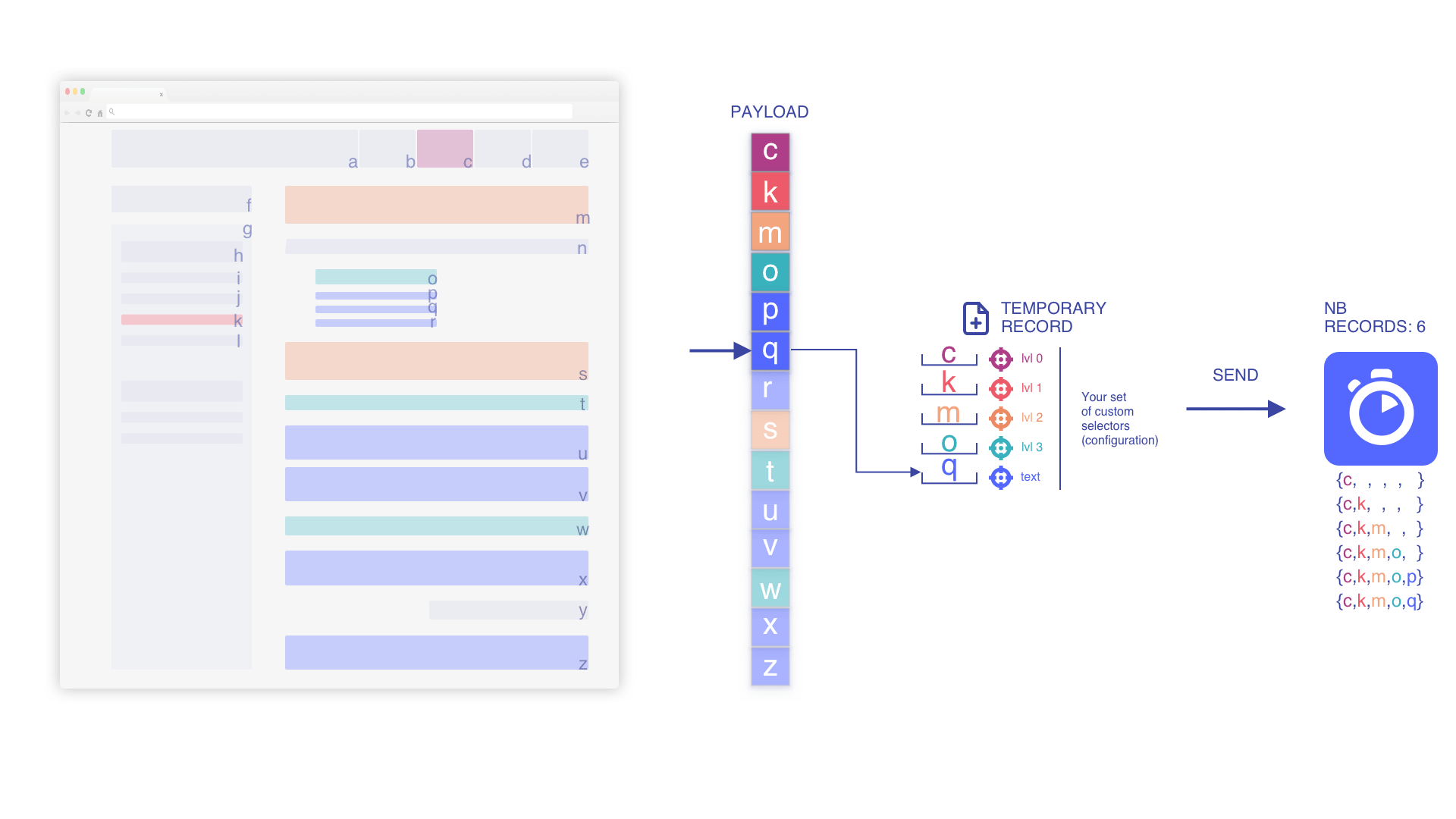
より高いレベルを追加する際にスタッシュされた深い要素を削除
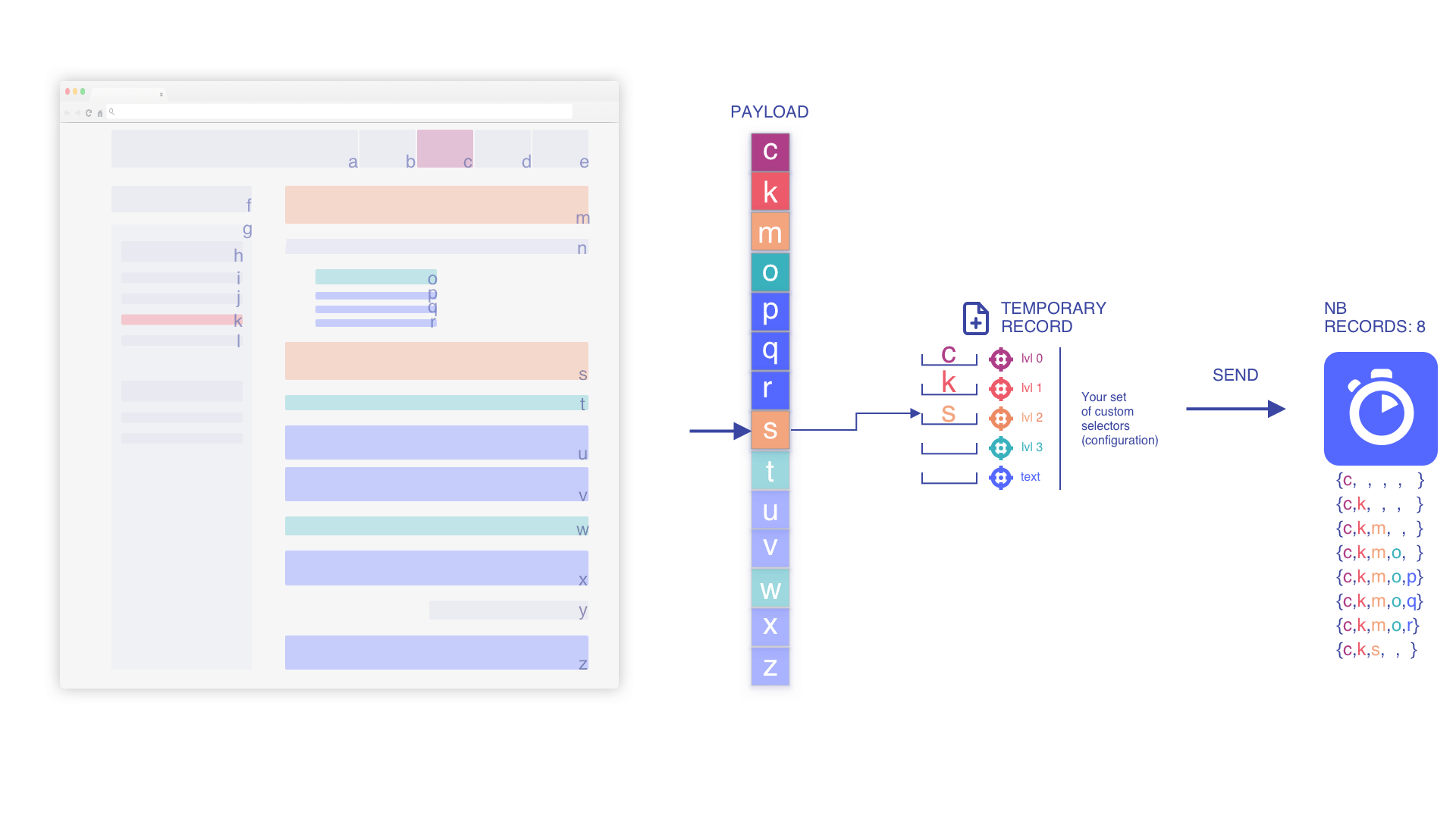
新しいレベルに遭遇したら、コンテキ�スト情報と階層を更新する必要があります。これは前のサブセクションに関連しない新しいサブセクションが開始されるためです。