Configuration requise
Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →
Cette section présente les bonnes pratiques pour optimiser notre indexation. L'adoption de ces spécifications est nécessaire pour permettre à notre crawler de créer la meilleure expérience à partir de votre site. Vous devrez modifier votre site et suivre ces règles.
Si votre site est généré par l'un de nos outils pris en charge, aucune modification n'est nécessaire car il respecte déjà nos exigences.
Exemple de configuration générique
Vous trouverez ci-dessous le modèle de configuration DocSearch par défaut, que vous pouvez ajuster avec des exemples de notre section sur les complex extractors.
Si vous utilisez l'une de nos intégrations, consultez la page des templates.
docsearch-default.js
new Crawler({
appId: 'YOUR_APP_ID',
apiKey: 'YOUR_API_KEY',
startUrls: ['https://YOUR_START_URL.io/'],
sitemaps: ['https://YOUR_START_URL.io/sitemap.xml'],
actions: [
{
indexName: 'YOUR_INDEX_NAME',
pathsToMatch: ['https://YOUR_START_URL.io/**'],
recordExtractor: ({ helpers }) => {
return helpers.docsearch({
recordProps: {
lvl0: {
selectors: '',
defaultValue: 'Documentation',
},
lvl1: ['header h1', 'article h1', 'main h1', 'h1', 'head > title'],
lvl2: ['article h2', 'main h2', 'h2'],
lvl3: ['article h3', 'main h3', 'h3'],
lvl4: ['article h4', 'main h4', 'h4'],
lvl5: ['article h5', 'main h5', 'h5'],
lvl6: ['article h6', 'main h6', 'h6'],
content: ['article p, article li', 'main p, main li', 'p, li'],
},
aggregateContent: true,
recordVersion: 'v3',
});
},
},
],
initialIndexSettings: {
YOUR_INDEX_NAME: {
attributesForFaceting: ['type', 'lang'],
attributesToRetrieve: [
'hierarchy',
'content',
'anchor',
'url',
'url_without_anchor',
'type',
],
attributesToHighlight: ['hierarchy', 'content'],
attributesToSnippet: ['content:10'],
camelCaseAttributes: ['hierarchy', 'content'],
searchableAttributes: [
'unordered(hierarchy.lvl0)',
'unordered(hierarchy.lvl1)',
'unordered(hierarchy.lvl2)',
'unordered(hierarchy.lvl3)',
'unordered(hierarchy.lvl4)',
'unordered(hierarchy.lvl5)',
'unordered(hierarchy.lvl6)',
'content',
],
distinct: true,
attributeForDistinct: 'url',
customRanking: [
'desc(weight.pageRank)',
'desc(weight.level)',
'asc(weight.position)',
],
ranking: [
'words',
'filters',
'typo',
'attribute',
'proximity',
'exact',
'custom',
],
highlightPreTag: '<span class="algolia-docsearch-suggestion--highlight">',
highlightPostTag: '</span>',
minWordSizefor1Typo: 3,
minWordSizefor2Typos: 7,
allowTyposOnNumericTokens: false,
minProximity: 1,
ignorePlurals: true,
advancedSyntax: true,
attributeCriteriaComputedByMinProximity: true,
removeWordsIfNoResults: 'allOptional',
separatorsToIndex: '_',
},
},
});
Vue d'ensemble d'une structure claire
Un site appliquant ces bonnes pratiques apparaîtra simple et parfaitement lisible. Voici un exemple d'aspect visuel :
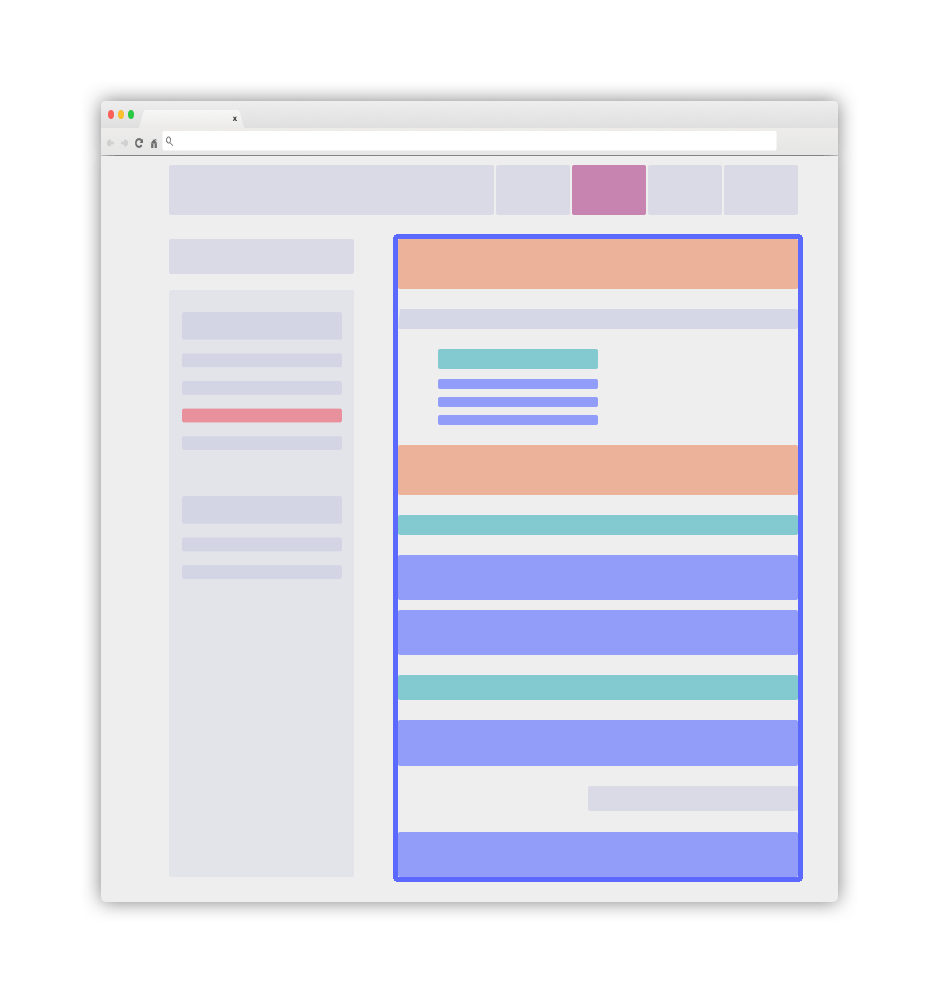
L'élément bleu principal correspondra à votre conteneur .DocSearch-content. Plus de détails dans les lignes directrices suivantes.
Utiliser les bonnes classes comme recordProps
Vous pouvez ajouter des classes statiques spécifiques pour nous aider à identifier le rôle de votre contenu. Ces classes ne doivent pas impacter le style. Ces classes dédiées nous permettront de créer une excellente expérience d'apprentissage au fil de la saisie pour votre documentation.
-
Ajoutez une classe statique
DocSearch-contentau conteneur principal de votre contenu textuel. Généralement, cette balise est un élément HTML<main>ou<article>. -
Tout élément
lvlconsultable en dehors de ce conteneur principal (par exemple dans une barre latérale) doit être un sélecteurglobal. Ils seront récupérés globalement et injectés dans chaque enregistrement construit à partir de votre page. Attention : la valeur de niveau est importante et chaque élément correspondant doit avoir un niveau croissant dans le flux HTML. Un niveauX(pourlvlX) doit apparaître après un niveauYlorsqueX > Y. -
Les sélecteurs
lvlXdoivent utiliser les balises de titre standard commeh1,h2,h3, etc. Vous pouvez aussi utiliser des classes statiques. Attribuez unidounameunique à ces éléments comme détaillé ci-dessous. -
Chaque élément DOM correspondant aux sélecteurs
lvlXdoit avoir un attributidounameunique. Cela permettra la redirection vers l'emplacement exact des éléments correspondants. Ces attributs définissent l'ancre à utiliser. -
Tout élément textuel (recordProps
content) doit être encapsulé dans une balise<p>ou<li>. Ce contenu doit être atomique et divisé en petites entités. Veillez à ne jamais imbriquer un élément correspondant dans un autre pour éviter les doublons. -
Restez cohérent et n'oubliez pas que nous avons besoin d'une homogénéité dans le flux HTML.
Intégrez des informations globales via des balises meta
Notre crawler extrait automatiquement les informations de nos balises meta spécifiques à DocSearch :
<meta name="docsearch:language" content="en" />
<meta name="docsearch:version" content="1.0.0" />
Le crawl ajoute la valeur content de ces balises meta à tous les enregistrements extraits de la page. L'attribut name des balises meta doit suivre le modèle docsearch:$NAME. $NAME correspond au nom de l'attribut défini pour tous les enregistrements.
La balise meta docsearch:version peut contenir des tokens séparés par des virgules, chacun représentant une version pertinente pour la page. Ces tokens doivent être conformes à la spécification SemVer ou ne contenir que des caractères alphanumériques (ex: latest, next, etc.). En tant que filtres à facettes, ces tokens de version sont insensibles à la casse.
Par exemple, tous les enregistrements extraits d'une page avec la balise meta suivante :
<meta name="docsearch:version" content="2.0.0-alpha.62,latest" />
L'attribut version de ces enregistrements sera :
version:["2.0.0-alpha.62", "latest"]
Vous pouvez ensuite transformer ces attributs en facetFilters pour les filtrer depuis l'interface.
Recommandations complémentaires
-
Votre site web doit disposer d'un sitemap mis à jour. Ceci est essentiel pour que notre crawler sache quels contenus mettre à jour. Ne vous inquiétez pas, nous continuerons à explorer votre site et à découvrir les hyperliens intégrés pour indexer votre excellent contenu.
-
Chaque page doit rendre son contexte complet disponible. L'utilisation d'éléments globaux peut y contribuer (voir ci-dessus).
-
Assurez-vous que le contenu de votre documentation reste accessible sans rendu JavaScript côté client. Si JavaScript est indispensable, vous devez définir
renderJavaScript: truedans votre configuration.
Des questions ? Contactez-nous sur Discord ou notre support.